
# Flask を Heroku にデプロイする
# 概要
flaskr を Heroku にデプロイします。 開発環境は macOS です。
ここからかなり長い前説に入ります。 早々にデプロイされたい方はこちらからどうぞ。
# flaskr
flaskr とは Flask の公式ドキュメントのチュートリアルで書かれているブログアプリです。 ちょっといま風のデザインとは違うのですが、公式ドキュメントに慣れるのは良いことだと思い採用しました。
なぜ公式ドキュメントに慣れるのが良いかというと、簡潔にベストプラクティスがまとまっているからです。 ただ、簡潔過ぎてよくわからないので最初は 市販の本、動画、オンライン学習システムで全体像を把握した方がやりやすいと思います。
いくつか書籍やオンライン学習サービスを集めました。 やったことはなく、オススメというわけではありません。
日本語ならオンライン学習サービスなら Paiza, PyQ さんなどが Flask のチュートリアルを出してくれています。
- Webアプリ開発入門 Flask編 (全5レッスン) - Paiza (opens new window)
- 49-1: FlaskでWebアプリケーションの動作を学ぼう - PyQ (opens new window)
書籍なら以下の通りです。
- ゼロからFlaskがよくわかる本: Pythonで作るWebアプリケーション開発入門 - Kindle (opens new window)
- PythonでWebサービスを作る - Python3 + Flaskで作るWebアプリケーション開発入門 - その1 (opens new window)
Udemy や YouTube を漁ると結構出てきます。 YouTube は無料なのですが、無料でこのクオリティか...と焦ります笑
- Python Flask Tutorial: Full-Featured Web App Part 1 - Getting Started - YouTube (opens new window)
- REST APIs with Flask and Python - Udemy (opens new window)
おそらく Flask を触る場合は、かなり必須に近いのではないかと思いました。 公式チュートリアルのコードを使用します。
# Heroku
Heroku とは作ったアプリを公開できるサーバです。
本当は Aamazon Web Services(AWS) にするべきでした。 最近のクラウドは AWS がかなり強いらしいです。
IT はスケールメリットが効くので、大きいところはますます強くなります。 実際、ドットインストールの「Heroku 入門」も更新が止まってしまっています。
それに Twitter などでも AWS やってる人募集してます! みたいなツイートを 2019/6/1~2019/7/14 までの間で3回見かけました。 Heroku はそういうのは見かけません。
Python の PaaS として Amazon Web Services が1位、Google Cloud Platform が2位、Heroku は3位みたいな、 そんなランキングをどこかで見かけました。 数字も調査対象も書かれてなかったので、そんなもんかくらいに流していたのですが。
よくわかっていないのですがおそらく Heroku と等価にあるのは Elastic Beanstalk(EB) です。 しかし EB の記事はあまり新しいものがありません。 おそらく最近は、みんな Docker コンテナに詰め込んで、それをデプロイする Elastic Container Service(ECS) を使っているのかもしれません。
- Elastic Beanstalk に Flask をデプロイ (opens new window)
- Elastic Container Service に Flask をデプロイ (opens new window)
ちなみに Heroku の dyno 自体はコンテナです。 Heroku にアップロードするとそれを Heroku がコンテナに詰め込んでデプロイしてくれているみたいです。 OS を貸し出してもらっていると思ったのですが、貸し出してもらっているのはコンテナのようでした。
コンテナ とは、 コンピューティングリソース、メモリ、OS、一時的なファイルシステムを備えた軽量の独立した環境です。 通常は複数個が同じホストで実行されますが、それぞれのコンテナは相互に完全に隔離された状態になっています。
Heroku で使用されるコンテナは「 dyno 」と呼ばれます。 dyno はユーザーが指定したコマンドにもとづいてコードを実行するように設計された Linux コンテナであり、それぞれが相互に隔離された状態で仮想化されています。
dyno:Heroku プラットフォームの中核 (opens new window)
なにが良いやり方なのかはわかっていません。 そもそも自分はいまだにコンテナが何かもわかっていません。 でも Heroku よりは AWS の方が良い気がします。
じゃあ Heroku を学習する意味がないのかと聞かれると、 強くはオススメできないかなと...
Heroku のメリットはとりあえず最初は無料で始められます。 クレカ登録しない限りは、どうあがいても課金されないはずです。
AWS は完全従量課金なので、間違えると死にます。
AWS を使うにしてもいくつか構成があります。 EC2, ECS, EB, Lambda を使うもの。思いつくだけで4つあります。
Lambda + API Gateway でサーバレスに決め込むのが、 いま風なやり方かもしれません。 いずれにせよ、選択をミスったことを先に白状しておきます。
Heroku のアドベントカレンダーも結構盛んなので、 Heroku で悪い訳ではないのですが、もしわかるなら AWS が安パイな感じがします。
- heroku Advent Calendar 2018 - Qiita (opens new window)
- Herokuのビジネス的な利用価値 - フレクトのクラウドblog re:newal (opens new window)
ワイの屍を超えて行ってください笑
# 問題
実は、 flaskr を採用してしまったことで3つの問題が生じてしまいました。 1つ目は、公式ドキュメントのチュートリアルは英語です。 2つ目は、チュートリアルの写経が面倒です。 3つ目は、24時間経つとデータが消えます笑
これら3つの問題に対して、こちらで書き換えたコードを事前に用意しました。 コードをダウンロードしていただきます。 ここでは Heroku へのデプロイに焦点を当てていきます。
# 1. 公式ドキュメントが英語問題
日本語で書かれた公式チュートリアルの補足を見つけました。
が、ただ、上記の解説してくれているページをもってしても、 公式チュートリアルは厳しいとこがあります。 いまだにわからないところだらけです。
なぜなら、ベストプラクティス集のようになっているからです。 「こんな時のために、こう書いておくと、とっても便利だよ!」って言われても、 初心者にはわからんのです笑
ただ、公式ドキュメントに慣れておいた方が良いと感じました。 何か突っ込んだことに関してわからないことがあったら、 公式ドキュメントに当たるしかないからです。
# 2. コードを書くのが面倒問題
公式チュートリアルのコードを写経するのは面倒です。 GitHub のページからダウンロードできます。 その手順も書かれています。
ただし、今回は後述させていただく理由から、 SQLite から PostgreSQL に、SQL 文から ORM の SQLAlchemy に書き換えています。
そのため、こちらで SQLAlchemy に書き換えたコードを用意しました。 ただ、ファイルの中のコードについては、基本的に取り扱いません。 今回はデプロイに主眼を当てて行きます。
差分については、GitHub のページに記載する予定です。 でも公式チュートリアルの補足があった方が良いのでは... と思いつつ。 今回は控えさせていただきます。
# 3. 24時間後には記憶喪失問題
公式ドキュメントのチュートリアル flaskr ではデータベースに SQLite を使用しています。
SQLite は、とても手間いらずで pip install せずに import sqlite3 さえすれば Python から使うことができます。
SQLite は、データをファイルに保存してくれます。
例えば下記の Qiita の記事のコードをコピペして実行して見てください。
すると database.db というファイルが作成されます。
この database.db というファイルの中にデータが保存されています。
ここで問題なのが、そんなとっても便利な SQLite を使ってデータベースを作っても、 Heroku の場合、時間が経つとデータベースのファイルが定期的に消されてしまうのです。
Heroku は 博士の愛した数式 (opens new window) みたいなやつなんです。
sqlite3 を Heroku で使ってはいけません。
django syncdb をしたあとに "no such table" エラーが Heroku で起こる - Stackoverflow (opens new window)
Disk backed storage - SQLite on Heroku (opens new window)
SQLite はメモリで動作し、ディスクのファイルにあるデータストアに保存します。
SQLite runs in memory, and backs up its data store in files on disk.開発時にはこの方法はうまくいきますが、 Heroku の Cedar スタックは一時的なファイルシステムを持っています。
While this strategy works well for development, Heroku’s Cedar stack has an ephemeral filesystem.あなたはそのファイルシステムに書くことも、読むこともできますが、 書き込まれたものは周期的に消されます。
You can write to it, and you can read from it, but the contents will be cleared periodically.もし SQLite を Heroku で使った場合は、 少なくとも24時間おきにデータベースの全てを失います。
If you were to use SQLite on Heroku, you would lose your entire database at least once every 24 hours.
そもそも Herokuのスタックとは? (opens new window)
Heroku は アプリケーション を Slag という 実行可能なプログラムの塊 にして、 その Slag を Dyno と呼ばれる環境へデプロイしてアプリケーションを実行させています。
この Slag の実行環境であるDynoが配備される際に、その元になるイメージ が スタック です。
イメージってなんだ?と思ったので調べました。OS のデータを丸々コピーしたものという理解でいいのだろうか...
OS を丸ごとバックアップする場合は、イメージバックアップ (opens new window) を行います。 イメージバックアップとは、ファイル単位ではなく、 ハードディスクのセクタ単位でバックアップを行い、 1つのファイル(イメージファイル)として保存することです。 イメージバックアップを行うと、MBRもバックアップできますし、 ファイルが使用されているかいどうかに関わらず、バックアップ可能がです。
バックアップ for OS (opens new window)
# NoSQL vs SQL
この記事が面白かったです。まあ SQL でいいかなと.., もっと精読したい。
ま、そんなわけで、NoSQLを語るときに「性能」を持ち出す人は、はっきり言って素人だと思います。 そうではなくて、SQLにないデータ構造の扱いやすさ、 ゼロから作った設計のモダンさ(MongoDBのレプリカセットは全自動で素晴らしい)などがメリットで、 そういった良さが生きる部分で「部分的に」使うのが正解だと思います。
それ以外の80%以上のユースケースでは、いまだSQLにまさるものはないでしょう。
MongoDBの様なNoSQLに勢いがあるのは何故ですか?SQLと比べてどんな利点や欠点がありますか? - Quora (opens new window)
この辺の記事も面白かった..., 全体的に普通は SQL だよね、みたいな空気感がある。
# SQLite3 vs Oracle vs MySQL vs PostgreSQL
そのため Heroku とは別のサーバを立ち上げて、データベースを作らないといけません。 サーバを立ち上げた時に何を使えば良いでしょうか?SQLite3, Oracle, MySQL, PostgreSQL といった選択肢が上がってきます。
今回は PostgreSQL を採用しました。 SQLite は、わざわざ別サーバを立てるのに使いたくないです。 Oracle は、無料ではないので使えません。お堅いことをするなら選択しますが。今回は趣味なので。 MySQL は、OSS 殺しの Oracle に買われたので使いたくありません。
Python を使う人は PostgreSQL を使う人が多いらしいです。 勉強になります。ありがとうございます。
集計のやりやすさが段違いです
— R(あいれい/おいす) (@R_farms) December 20, 2019
ポスグレさん善き
やっと時間と体力があるので #技書博 で買った本みてる。
— くず/カナタニチアキ🖥️いまさらRPA書いた (@kuzu_doh) December 21, 2019
「PostgreSQLから始めるデータベース生活」2冊。PostgreSQL触るときにはじめに当たりそうな事項について簡潔にまとめられていて良いです。第2段でPython+Flask+SQLAlchemyでアプリ作ったりも。委託してないのかな…https://t.co/o1ZPIbSWzP
あとは Python の Udemy の講師の方の講座の一覧を見ても PostgreSQL はあっても MySQL はない。
MySQL でも PostgreSQL どちらも、性能面ではあまり変わらない様子。
PostgreSQL と MySQL、使うならどっち? (opens new window)
とはいえ、バージョンが上がるごとに PostgreSQL も MySQL も高性能になってきているので、 結局は使いたい方を使えばいいんじゃないでしょうか。
MariaDB(MySQL) PostgreSQL どちらを選ぶか? (opens new window)
MySQL にも少し触れる。 商用 SQL データベースの大手のORACLEが著作権・商標権をもっていることやライセンスやの問題から、 昨今のLinuxの各ディストリビューションでは MySQL から派生した MariaDB が採用されていることが多い。 私もMySQLはあまり使用していない。
ただ Google Trend を見てみると MySQL の方が高いシェアを保っています。 ネットの雰囲気を見ていてもウェブ開発周りは MySQL が多い気配を感じます。 ただどうにもこうにも MySQL を持っていた Sun が Oracle に買われて以降、 ネガティブな印象が拭きれない... 個人的に...
- Google Trend - MySQL vs PostgreSQL (opens new window)
- MariaDB(MySQL) PostgreSQL どちらを選ぶか? - Qiita (opens new window)
# SQL vs ORM
ORM として Flask-SQLAlchemy を使用します。 ORM を使う理由は、以下2点からです。
まず第一に SQLite, PostgreSQL, MySQL で文法に若干の差分があること。 また第二に OAuth と連携させる時に Flask Dance というライブラリを使うのですが、 その全てのサンプルコードが ORM(SQLAlchemy) であることなどを考慮しました。
Flask Dance に限らず Flask のサンプルコードで Flask-SQLAlchemy が使われてしまっていて、 使うのがベターなのかなと思いました。
ORM を使うか、悩んみました。ORM を使うか、使わないかは、よくネットで見かけます。 個人的に SQL に不慣れなところもあって ORM は外したかったのですが、 上記の理由から今回は採用しました。
# 工程
作業工程は以下の4つに分けられます。
- データベース 周りのセットアップ
- Python 周りのセットアップ
- Git 周りのセットアップ
- Heroku 周りのセットアップ
全体の作業工程は以下のようなものです。 結構、長いです。
# 第一工程 データベース
PostgreSQL をインストールしていきます。 ドットインストールで全体像を掴んでおくと、理解が速いかもしれません。 PostgreSQL は無料でした笑
# Step 1. インストール
以下のコマンドで PostgreSQL をインストールしてください。
$ # PostgreSQL をインストール
$ brew install postgresql
macOS での PostgreSQL の操作はこちらによくまとまっています。 主にこちらを参考にさせていただきました。
# Step 2. データベースサーバの起動
PostgreSQL のデータベースサーバが起動します。
$ postgres -D /usr/local/var/postgres
postgres コマンドをデータベースサーバを起動します。
公式ドキュメントの説明が難しい...笑
postgres (opens new window)
postgresは、PostgreSQLのデータベースサーバです。 クライアントアプリケーションがデータベースに接続するためには、 稼働中のpostgresインスタンスに(ネットワークを介して、またはローカルで)接続する必要があります。 その後、postgresは接続を取り扱うために別のサーバプロセスを開始します。
-D オプションは設定ファイルが書かれている場所を指定するようです。
-D (opens new window)
ファイルシステム上のデータベース設定ファイルの場所を指定します。 詳細は 項18.2 (opens new window) を参照してください。
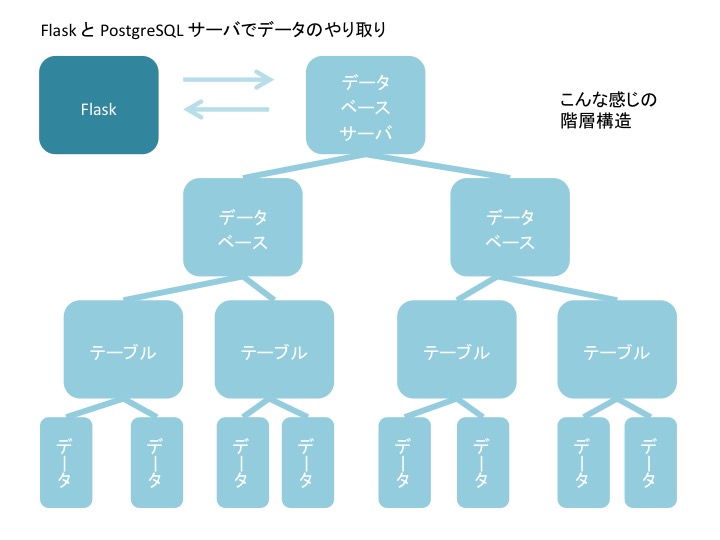
「データベースサーバ」を起動して「データベース」を作成してって言われるとなんだか難しいです。 自分はこんな感じの階層構造をイメージしています。
「ウェブ」にも「ウェブサーバ」がある様に、「データベース」にも「データベースサーバ」がある、というのもまた 理解へのポイントかなと思ったりします。
# Step 3. ユーザの作成
今回は flaskr_user というユーザ名にします。
$ createuser flaskr_user --pwprompt
createuser (opens new window)
createuserは新しいPostgreSQLのユーザ(より正確にいえばロール)を作成します。
--pwprompt (opens new window)
このオプションが指定されると、createuserは新しいユーザのパスワードのプロンプトを表示します。 もしパスワード認証を使う予定がなければ、これは必要ありません。
# Step 4. データベースの作成
今回は flaskr_db, test_flaskr_db という2つのデータベースを作成します。
1つのデータベースサーバの中に複数のデータベースを作ることができます。
ちなみになぜ今回2つのデータベースを作成したかというと、 公式チュートリアルにテストコードもついていたので、 テスト用のデータベースも合わせて作成しています。
$ # createdb データベース名 --owner ユーザ名
$ createdb flaskr_db --owner flaskr_user
$ createdb test_flaskr_db --owner flaskr_user
createdbは、新しいPostgreSQLデータベースを作成します。
通常、このコマンドを実行したデータベースユーザが、新しいデータベースの所有者になります。 ただし、コマンドを実行するユーザが適切な権限を持っている場合、
-Oオプションを使用して別のユーザを所有者に指定することができます。
# 確認する - データベース
作成したデータベースを確認します。
$ psql --username flaskr_user --list
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges
----------------+-------------+----------+---------+-------+-------------------
flaskr_db | flaskr_user | UTF8 | C | UTF-8 |
test_flaskr_db | flaskr_user | UTF8 | C | UTF-8 |
--list (opens new window)
利用可能な全てのデータベースを一覧表示し、終了します。 この他の接続に関連しないオプションは無視されます。 \listメタコマンドと似た効力を持ちます。
# 確認する - ユーザ
作成したユーザを確認します。
psql を打ち込むと「対話的ターミナル」が起動します。
Python で言うところの対話モード >>> ですね。
以下のコマンドでは flaskr_db というデータベースに flaskr_user というユーザとしてログインしています。
$ psql --username flaskr_user --dbname flaskr_db
psql (opens new window)
psqlとはPostgreSQLのターミナル型フロントエンドです。 対話的に問い合わせを入力し、それをPostgreSQLに対して発行して、結果を確認することができます。 また、ファイルから入力を読み込むことも可能です。 さらに、スクリプトの記述を簡便化したり、 様々なタスクを自動化したりする、いくつものメタコマンドとシェルに似た各種の機能を備えています。
\du を打ち込み作成したユーザ flaskr_user がいるか確認します。
対話的
flaskr_db=> \du
List of roles
Role name | Attributes | Member of
-------------+------------------------------------------------------------+-----------
flaskr_user | | {}
flaskr_db=>
\du (opens new window)
データベースロールを一覧表示します。 ("ユーザ"と"グループ"という概念は"ロール"に統合されましたので、 このコマンドは\dgと同じものになりました。)
メタコマンド (opens new window)
psql内で入力されたコマンドのうち、引用符で囲まれていないバックスラッシュで始まるものは、 psql自身が実行するpsqlのメタコマンドとして扱われます。 これらのコマンドを使うと、データベースを管理したりスクリプトを作成するにあたって、 psqlがより便利になります。 メタコマンドはよくスラッシュコマンド、 またはバックスラッシュコマンドとも呼ばれます。
# 補足 理解へのポイント
# ユーザとデータベースの関係
正直言ってよくわかっていません。
psql コマンドを使って「対話問い合わせ」をできるようにするには、
--dbname オプションを使いデータベースを指定する必要がありました。
ユーザを作成すると全てのデータベースに紐づいてしまうのか
このとき \du コマンドを打ち込むと全てのユーザが表示されます。
この辺りは「ロール」をキーワードにして検索して調べていく他なさそうです。
# コマンド
普通 brew install モニョモニョ すると
モニョモニョ コマンドだけが追加されます。
しかし postgresql は別です。
他の様々なコマンドが追加されます。
postgre コマンド以外のコマンドは、クライアントアプリケーションと
サーバアプリケーションの2つに大別されるようです。
そのコマンドの一覧は、こちらにあります。
クライアントアプリケーションとサーバアプリケーションの違いがわからないのですが、 以下が参考になりそうです。
1.2. 構造的な基本事項 - PostgreSQL 9.4.5文書 (opens new window)
先に進む前に、PostgreSQLシステム構成の基礎を理解すべきです。 PostgreSQLの各部分がどのように相互作用しているかを理解することにより、本章の内容がわかりやすくなります。
データベースの用語で言うと、PostgreSQLはクライアント/サーバモデルを使用しています。 PostgreSQLのセッションは以下の協調動作するプロセス(プログラム)から構成されます。
- サーバプロセス。 これは、データベースファイルを管理し、クライアントアプリケーションからのデータベースの接続を受け付け、クライアントに代わってデータベースに対する処理を行います。 データベースサーバプログラムはpostgresと呼ばれています。
- ユーザの、データベース操作を行うクライアント(フロントエンド)アプリケーション。 クライアントアプリケーションはその性質上非常に多様性があります。 テキスト指向のツール、グラフィカルなアプリケーション、データベースにアクセスしWebページを表示するWebサーバ、あるいはデータベースに特化した保守ツールなどがあります。 PostgreSQLの配布物では、いくつかのクライアントアプリケーションを用意しています。 そのほとんどはユーザによって開発されました。
# 第二工程 Python
# Step 5. flaskr をダウンロード
公式チュートリアルのソースコードを写経するのは面倒なので、ダウンロードします。
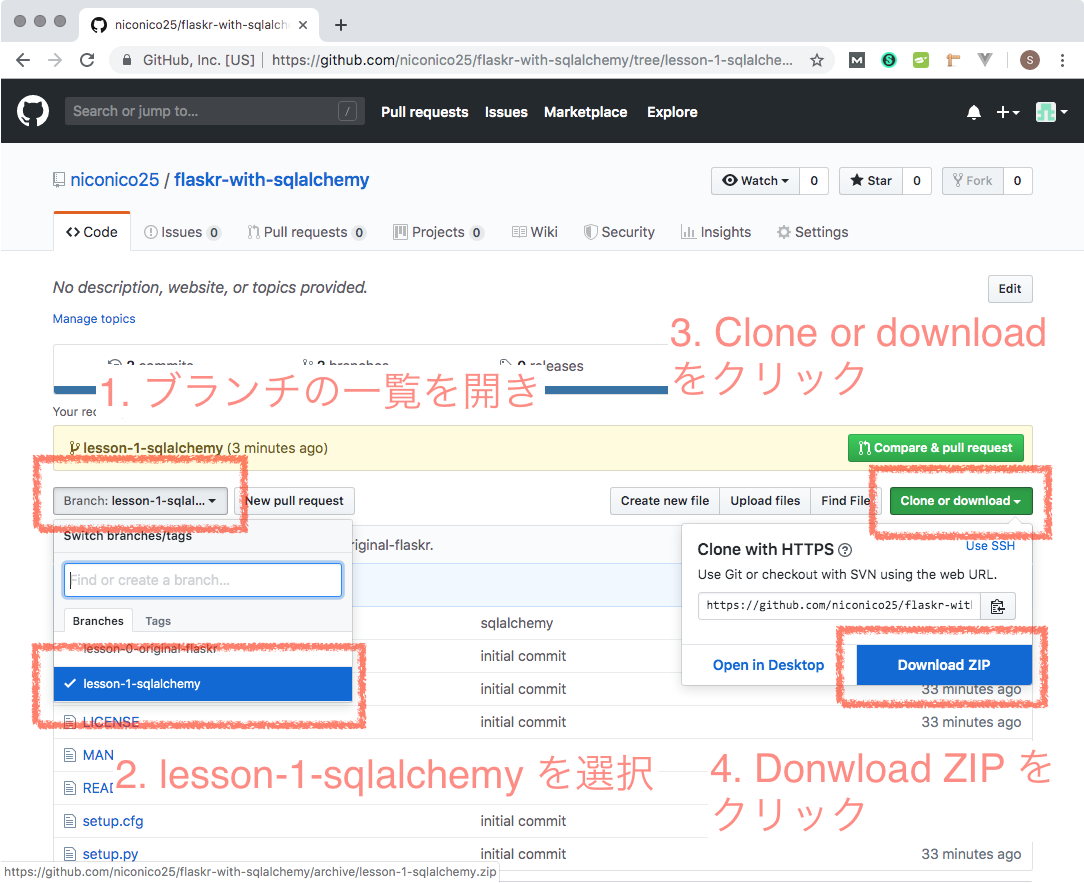
# (1) アクセス
以下のページにアクセスします。
# (2) ダウンロード
Clone or download > Download ZIP というボタンがあるので、クリックする。
# (3) カレントディレクトリを移動
カレントディレクトリをダウンロードした tutorial ディレクトリに移動してください。
# Step 6. 仮想環境の構築
仮想環境を作成します。
# (1) 仮想環境を作成する
$ python3 -m venv venv
# (2) 仮想環境を設定する。
venv/bin/activate の一番下に下記のスクリプトを追加してください。
# 書式
export FLASK_APP=flaskr
export FLASK_ENV=development
export PORT=ポート番号
export DATABASE_URL="postgresql://ユーザ名:パスワード@127.0.0.1:5432/データベース名"
export TEST_DATABASE_URL="postgresql://ユーザ名:パスワード@127.0.0.1:5432/test_データベース名"
export PYTHONPATH="カレントディレクトリのパス"
# 例
export FLASK_APP=flaskr
export FLASK_ENV=development
export PORT=5000
export DATABASE_URL="postgresql://flaskr_user:[email protected]:5432/flaskr_db"
export TEST_DATABASE_URL="postgresql://flaskr_user:[email protected]:5432/test_flaskr_db"
export PYTHONPATH="/Users/user/tutorial"
# (3) 仮想環境を有効にする
以下のコマンドを打ち仮想環境を有効にしてください。
$ . venv/bin/activate
この時 venv/bin/activate が実行されています。
(2) で設定した export から始まるコマンドが実行されます。
上記の様に環境変数に設定を書き込むメリットはなんでしょうか?
まず第一に、文字通り環境ごとに設定を変更することができます。 例えば Heroku の環境変数 DATABASE_URL には、 自動的に PostgreSQL への URL が設定されます。
また第二に、パスワードなどの繊細な情報をファイルに書き込まなくて済みます。 ファイルに書き込むのと環境変数に書き込むの何が違うのか?という話なのですが。
環境変数を使えば、必要とされている場所だけに設定を記述することができます。 これをファイルに書き込んでしまうと、GitHub に上げた時にパスワードが書きっぱなしだったとか そういうことも避けられます。 実際にそういう事例を Twitter か何かで見かけました。
DATABSE_URL の書式の公式ドキュメントは、以下の通りです。
# Step 7. Flask をインストール
Flask をインストールします。
$ pip install flask
# Step 8. psycopg2 と Flask-SQLAlchemy をインストール
Flask-SQLAlchemy は ORM ラッパです。 PostgreSQL を操作するためには、Flask-SQLAlchemy だけでは操作できません。
Flask-SQLAlchemy から psycopg2 を経由して操作する必要があります。 psycopg2 は PostgreSQL を操作するライブラリです。
$ pip install Flask-SQLAlchemy psycopg2
ちなみに psycopg2 の psyco は psyco (opens new window) を、 pg は PostGre を、 2 は PEP 249 で定義された Python データベース API のバージョンを、 それぞれ表しているらしいです。
- What does "psycopg" stand for? - reddit (opens new window)
- psycopg2 でよくやる操作まとめ - Qiita (opens new window)
# Step 9. テーブルの作成
以下のコマンドを実行してください。
$ flask init-db
# 確認する - テーブル
データベースにログインして \dt コマンドを打ち込んでください。
$ psql --dbname flaskr_db --username flaskr_user
flaskr_db=> \dt
データベースが作成されていれば成功です。
flaskr_db=> \dt
List of relations
Schema | Name | Type | Owner
--------+------+-------+-------------
public | post | table | flaskr_user
public | user | table | flaskr_user
(2 rows)
flaskr_db=>
# 確認する - Flask
$ flask run
http://127.0.0.1:5000/ にブラウザでアクセスして、問題なくアプリが動作するか確認してください。
# 補足 flask コマンド
pip install flask すると flask コマンドが使えるようになります。
# flusk init-db
flask init-db コマンドは、テーブルが存在すれば削除して、
テーブルを作成するということをしています。
# flusk run
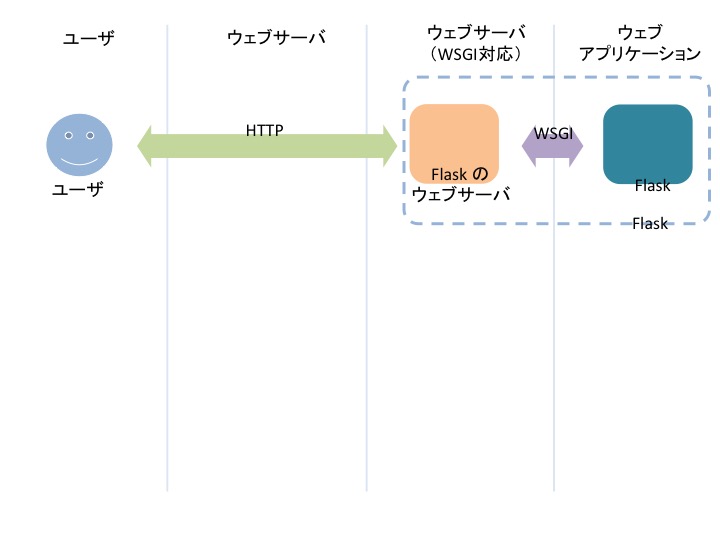
flask run は開発用のサーバを起動しています。
Flask は実は自分自身の中に開発用のサーバを持っています。
自分自身の中に持っているというのが、ちょっと理解しにくいのですが...
ただし「開発用」なので、このまま展開したらいけないよ!という注意書きが書かれます。
$ flask run
* Serving Flask app "flaskr"
* Environment: production
WARNING: This is a development server. Do not use it in a production deployment.
注意: これは開発サーバです。これを公開しないでください。
Use a production WSGI server instead.
* Debug mode: off
* Running on http://127.0.0.1:5000/ (Press CTRL+C to quit)
なぜいけないのかは書かれていません。セキュリティの問題なのか、それとも大量の接続を扱えないからということなのかはわかりません。
セキュリティの問題がなければ、性能が悪かろうが、いまはチュートリアルなので、そのまま展開してしまうのですが... その辺のことがわからないので、とりあえず専用のウェブサーバをインストールします。
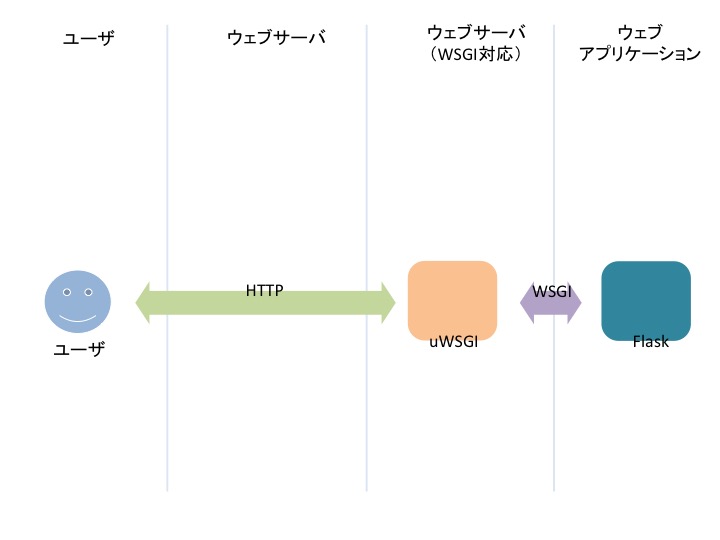
# Step 10. uWSGI をインストール
uWSGI は WSGI 対応のウェブサーバです。
$ pip install uwsgi
# 確認する
以下のコマンドを押下して、ウェブページが閲覧できるか確認してください。
$ # uwsgi --http IPアドレス:ポート --module 'ファイル名:Flaskオブジェクトを返す関数名'
$ uwsgi --http 127.0.0.1:5000 --module 'flaskr:create_app()'
例に漏れず、一通り引っかかるだけ引っかかり、Stackoverflow 先生にお世話になりました。
- Adding concurrency and monitoring - uWSGI (opens new window)
- uwsgi invalid request block size - Stackoverflow (opens new window)
- deploying flask app with uwsgi and flask-script Manager - Stackovervlow (opens new window)
# 補足 理解へのポイント
# Heroku の構成
Heroku は Heroku 自身でサーバを持っている様です。
この Heroku 自身がサーバを持っているというのは、どういうことでしょうか?
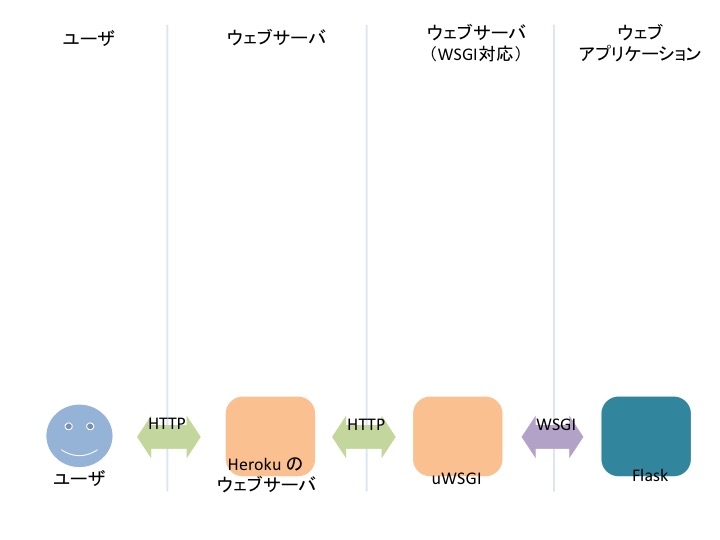
どうも負荷分散のために設けている様です。ただ、詳しいことはわかりません。
Routing - Heroku Dev Center (opens new window)
Inbound requests are received by a load balancer that offers SSL termination. From here they are passed directly to a set of routers.
The routers are responsible for determining the location of your application’s web dynos and forwarding the HTTP request to one of these dynos.
Heroku にまで手を出してしまい、ちょっとお手つき感がありますが、ここまで見てきた構成をまとめると以下の様になります。
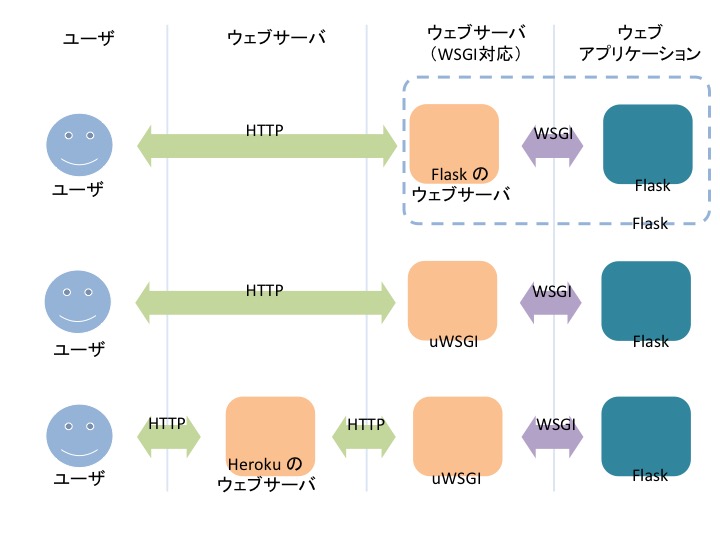
# WSGI ってなに?
しれっと WSGI と書き込まれています。WSGI とはなんでしょうか? HTTP リクエストがあるとウェブサーバは、 関数で Flask を呼び出しています。 WSGI とは関数の仕様です。 まあ、なんのこっちゃ?って感じなのですが、以下の動画を見るとわかりやすいです。
Flask そっくりのウェブアプリケーションをゼロから書いてくれています。 とても良い動画だと思いますが、見なくてもこの先に進めます。
# 第三工程 Git
ざっくり全体像は把握しておいた方が良いかな...と。 自分は Paiza の無料キャンペーンの時にやりました。 いまもあまり理解はしていません...
# Step 11. Git をインストールする。
$ brew install git
# Step 12. Git リポジトリをローカルに作成する。
Git リポジトリ (opens new window) を作成する。 以下のコマンドを実行してください。
$ git init
すると Git の設定ファイルが作成されます。
$ cat .git/config
[core]
repositoryformatversion = 0
filemode = true
bare = false
logallrefupdates = true
ignorecase = true
precomposeunicode = true
$
僕には違和感だったのですが、カレントディレクトリ、 いまいるディレクトリをリポジトリにします。
git init (opens new window)
空の Git リポジトリを生成するか、 すでに存在している Git リポジトリを再初期化します。
Create an empty Git repository or reinitialize an existing one.
# Step 13. GitHub アカウントを作成する。
説明は割愛させてください。 Google で検索するとやり方がたくさん出てきます。
# Step 14. Git リポジトリを GitHub に作成する。
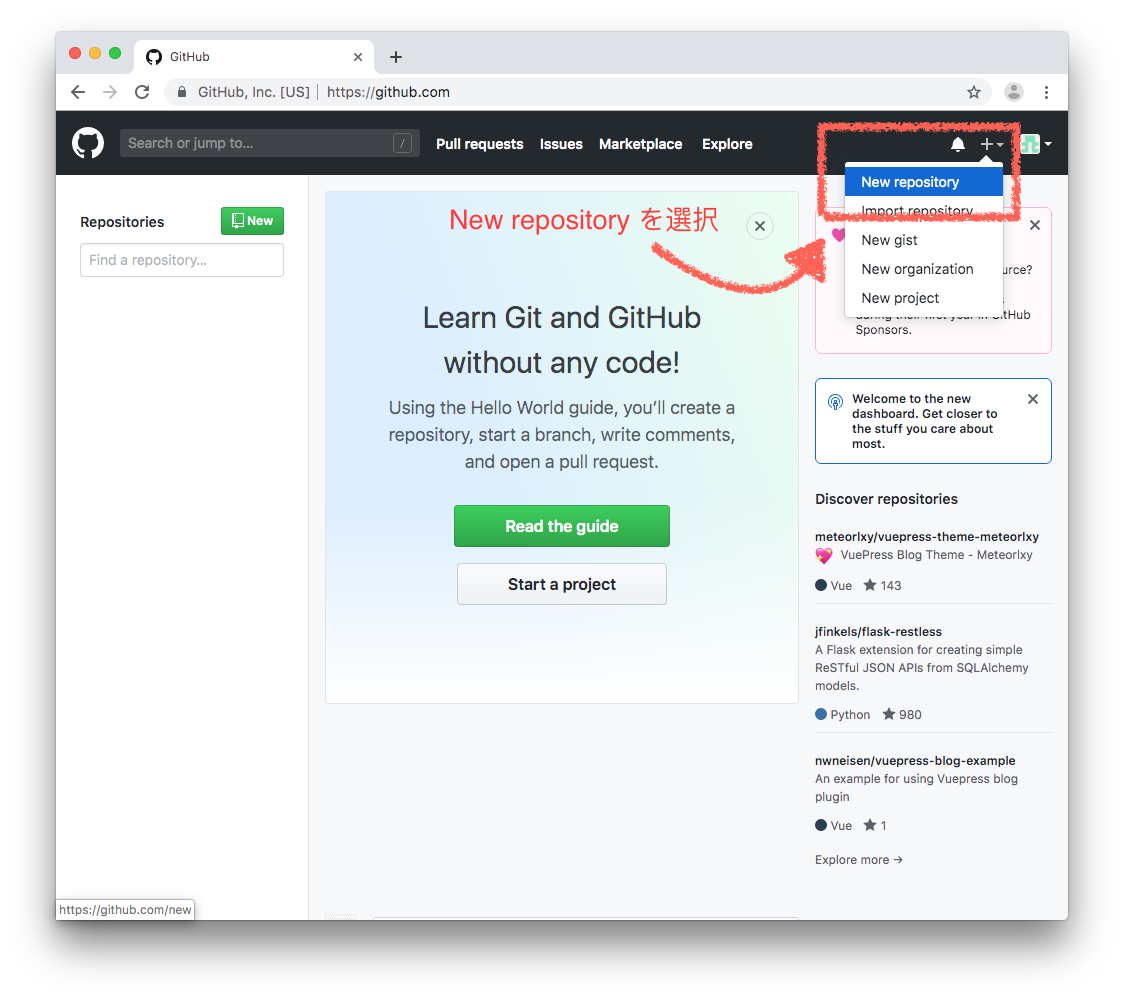
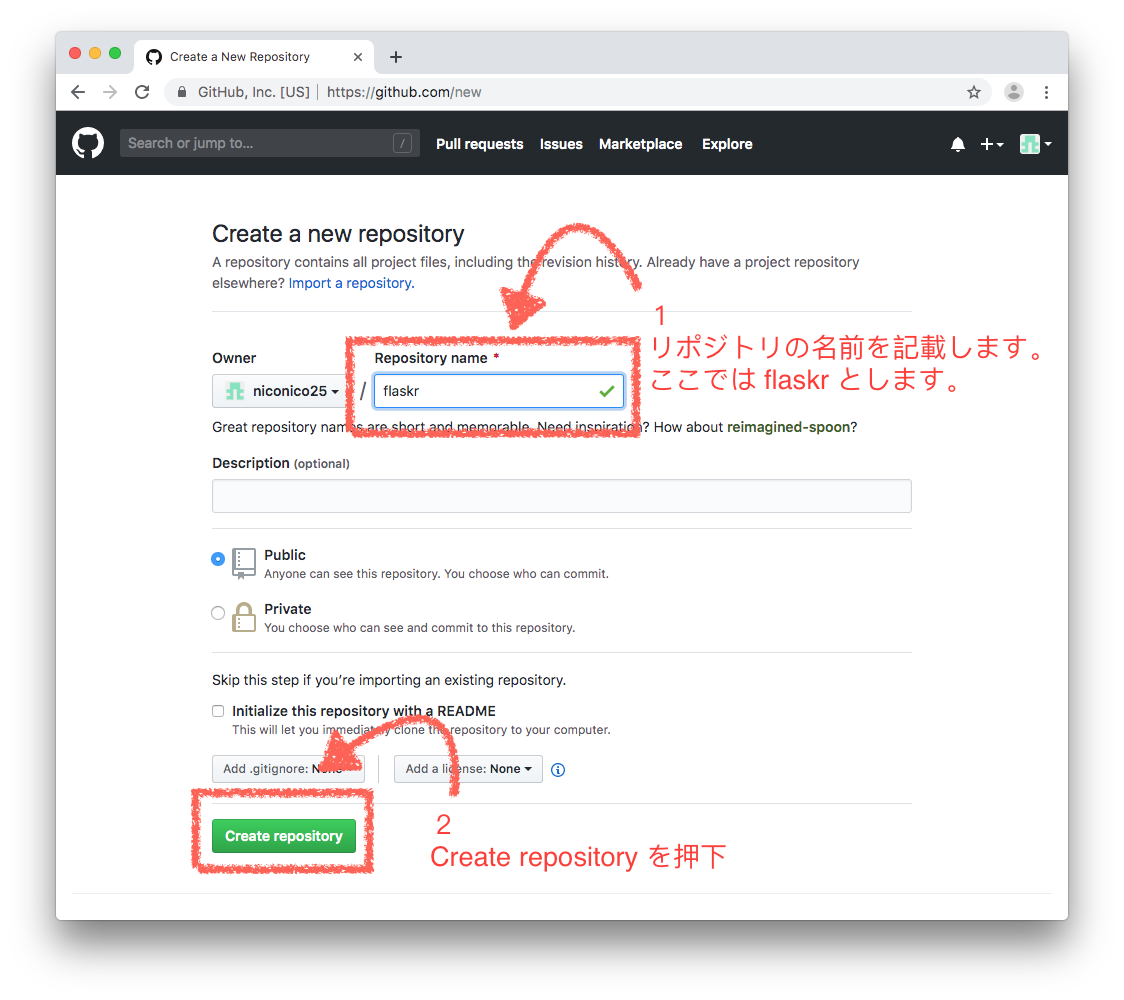
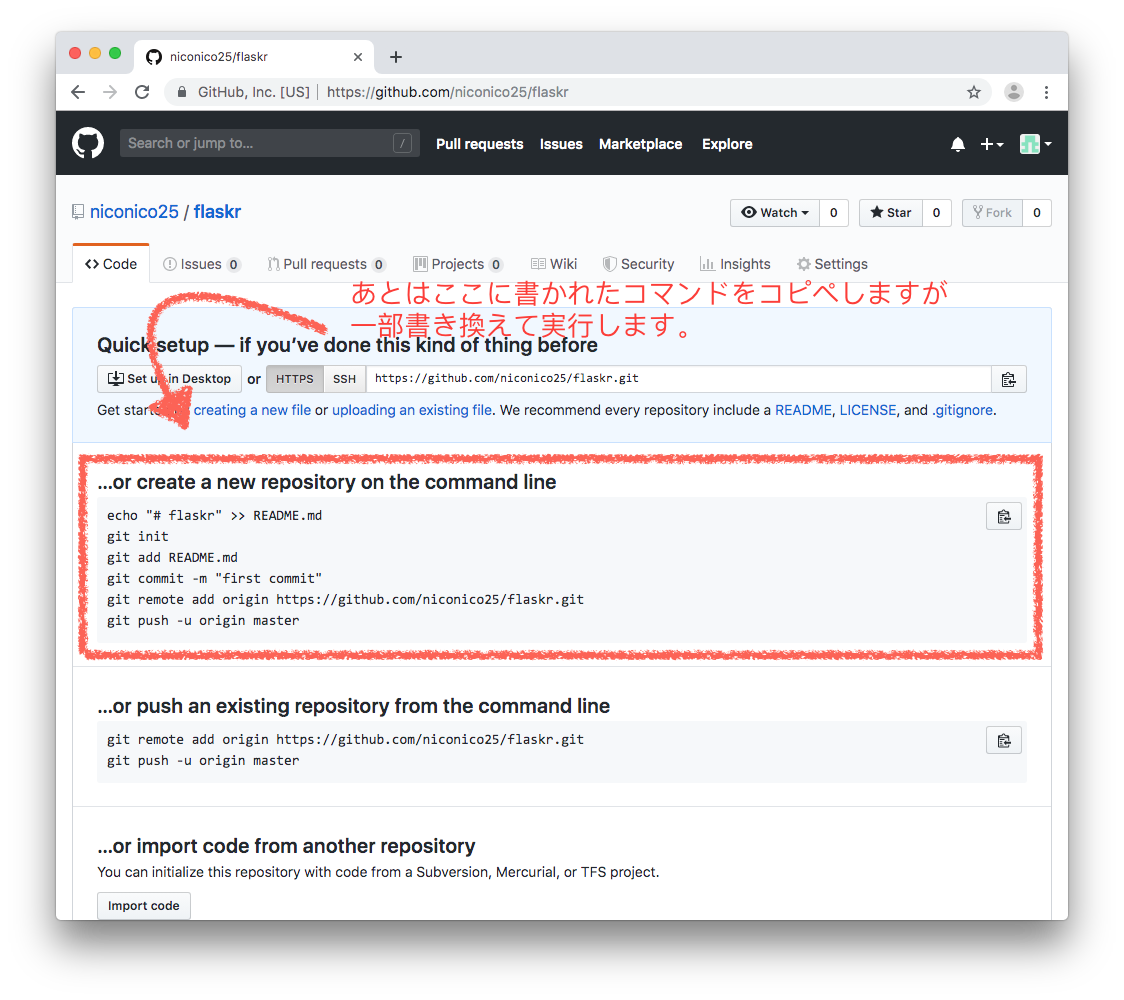
# Step 15. GitHub に作成したリポジトリをリモートに追加する。
Git のイメージつきやすいかなと思うので GitHub にもアップロードしてみましょう。
git remote add origin https://github.com/niconico25/flaskr.git
リモートが追加されているのを確認してみましょう。
$ cat .git/config
[core]
repositoryformatversion = 0
filemode = true
bare = false
logallrefupdates = true
ignorecase = true
precomposeunicode = true
[remote "origin"]
url = https://github.com/niconico25/flaskr.git
fetch = +refs/heads/*:refs/remotes/origin/*
$
# Step 16. GitHub の Git リポジトリに保存する。
git push -u origin master
# 補足 Git って難しい。
Heroku を触るにあたって Git を使わないといけません。 もう本当に何言ってるかわかりませんでした笑 GitHub で指定されているコマンドと Heroku で指定されているコマンドの違いがです。
# リモートとは?
リモートとはファイルの保存先のようなものらしいです。
リモートリポジトリ (opens new window)
専用のサーバに配置して複数人で共有するためのリポジトリです。
# add remote
今回見たように複数のリモート GitHub と Heroku にadd することができます。
# git add, git commit, git push の違い。
致命的ですね笑 なにを commit するか選択できる。 こうしておくと便利なんですよ、みたいなもやっとした説明で本気で辛かった笑
stage と index - 誰得UNIX (opens new window)
git addの存在理由を理解するためには、まずstageとindexという概念を理解しましょう。 git はチェックアウトされたファイルを編集した直後にcommitを実行しても、どのファイルも新しいバージョンとして登録されません。新しいバージョンとして登録するにはこのgit addをつかって、「このファイルは次回のコミットに含める」と宣言してやる必要があります。
このようにある変更点を次回のコミットに含めるようgitに指示することをgit用語で 「stageする」とかstagingと言います。 また、ワーキングコピーからstageした内容を保持する領域のことをindexと呼びます。
indexは、コミットを永遠に記録するリポジトリと、 ワーキングコピーとの間にある 緩衝地帯 であると考えると理解しやすいと思います。
# 第四工程 Heroku
ドットインストールの Heroku 入門がわかりやすいです。 ユーザ登録さえすれば「Heroku 入門」は、無料で見れます。
難点は、更新が終了していて少し情報が古いのと、 扱っている情報が Ruby on Rails になります。
ただ Heroku とは何かや全体像を知るには便利です。 けさ方、自分も見ていて勉強になるわーと思いました笑
Heroku の公式ドキュメントのチュートリアルは以下になります。 1, 2 までは同じですが 3 の Prepare the app 以降はこちらでやります。
- 1. Introduction (opens new window)
- 2. Set up (opens new window)
- Prepare the app
ちなみに 3 の Prepare the app は Git から Django のアプリケーションを Clone しています。 ありとあらゆるものがへしょららていて、 はじめて Heroku を触ったときは本当に謎でした。
# Step 17. Heroku のアカウントを作成する。
こちらの説明は省略させていただきます。
公式チュートリアルの以下の項目に該当します。
# Step 18. Heroku CLI をインストールする。
$ brew install heroku/brew/heroku
公式チュートリアルの以下の項目に該当します。
コマンドの一覧はこちら。
# 補足 CLI vs GUI
ちなみにブラウザの画面からも操作できます。 しかし、コマンドでやっていきます。 コマンドの方が、説明が簡単だからです笑
画面でぽちぽちやるのは、じつは手順書を作るのが鬼のように面倒になるんですよね。 あと、大量の設定を投入するときに死にます。 昔、死にました。心を無にして設定投入をしていました。
# Step 19. Heroku アプリの作成を作成する。
heroku コマンド一発で Heroku のアプリを作成できます。
$ heroku create
# 1. 確認する。
アプリが作成されているか、確認してください。
$ heroku pg:info
以下は出力例です。boiling-wave-66769 は Heroku のアプリ名称です。
$ heroku pg:info
⬢ boiling-wave-66769 has no heroku-postgresql databases.
$
# 2. どうやって連携しているの?
さて git init したものと heroku create したものが、 どこでどう連携しているのでしょうか?
それは .git/config ファイルです。
heroku create を実行すると heroku というリモートが生成されます。
アプリを生成すると、git リモート(この git リモートには
herokuと名前がつけられます)も生成され、 ローカルの git リポジトリと関連づけられます。 When you create an app, a git remote (calledheroku) is also created and associated with your local git repository.
Deploy the app - Getting Started on Heroku with Python (opens new window)
Git の設定ファイルを見るとリモート [remote] が追加されているのが、わかります。
$ cat .git/config
[core]
repositoryformatversion = 0
filemode = true
bare = false
logallrefupdates = true
ignorecase = true
precomposeunicode = true
[remote "heroku"]
url = https://git.heroku.com/boiling-wave-66769.git
^^^^^^^^^^^ この URL にアップロードしますよ という意味合い
になります。
fetch = +refs/heads/*:refs/remotes/heroku/*
$
そのため Git リポジトリが作成されていないディレクトリで heroku コマンドを打ち込んだ場合、
-a または --app オプションでアプリ名を指定してくださいというエラーが投げ返されます。
$ heroku pg:info
Error: Missing required flag:
-a, --app APP app to run command against
See more help with --help
$
わりかしよく見かけるエラーです。
# Step 20. 三種の神器を錬成する。
以下の3つのファイルを作成してプロジェクトディレクトリ直下に作成する必要があります。
runtime.txt ... Python のバージョン
requirements.txt ... 使用する Python のライブラリ
Procfile ... アプリケーションの起動方法
この3つのファイルは Heroku 三種の神器です。 macOS なら以下のコマンドでサクッと作成できます。
python -V | sed -n "s/Python /python-/p" > runtime.txt
pip freeze > requirements.txt
echo "web: uwsgi --http-socket :\$PORT --module 'flaskr:create_app()'" > Procfile
Windows でも手書きで簡単に作れます。 以下にそれぞれのファイルを解説します。
# (1) runtime.txt
# 確認
python -V コマンドを実行して Python のバージョンを確認してください。
$ python -V
Python 3.7.3
$
# 記載
その結果を runtime.txt に書き込んでください。
以下のような書式です。
行頭が小文字で、ハイフン - がつくことに注意してください。
python-3.7.3
runtime.txt に関する公式ドキュエントはこちら。
# これをしないとどうなるか
runtime.txt を忘れると
Git のエラーのように表示されるので気付きにくい感じです。
# (2) requirements.txt
# 確認
人によって結果は異なるはずです。
基本的に pip install したもの
Flask, psycopg2, SQLAlchemy, uWSGI の文字が見えていれば OK です。
$ pip freeze
Click==7.0
Flask==1.1.1 <--- 1) この文字が見えていれば基本は OK
Flask-SQLAlchemy==2.4.0
itsdangerous==1.1.0
Jinja2==2.10.1
MarkupSafe==1.1.1
psycopg2==2.8.3 <--- 2) この文字が見えていれば基本は OK
SQLAlchemy==1.3.5 <--- 3) この文字が見えていれば基本は OK
uWSGI==2.0.18 <--- 4) この文字が見えていれば基本は OK
$
# 記載
pip install したものを runtime.txt 記述します。
だいたい、以下のような書式です。
Flask==1.1.1
Flask-SQLAlchemy==2.4.0
itsdangerous==1.1.0
Jinja2==2.10.1
MarkupSafe==1.1.1
psycopg2==2.8.3
SQLAlchemy==1.3.5
uWSGI==2.0.18
# これをしないとどうなるか
pip install したあとは、requirements.txt を更新してください。 忘れてエラーになっているのを、割とよく見かけます。
- Python × Flask × Heroku のApp crashed ... について - teratail (opens new window)
- herukoでpythonのフレームワークbottleを使用したアプリケーションをデプロイしたいがうまくいかない (opens new window)
- Heroku のPythonチュートリアルで ... - teratail (opens new window)
新しく pip install したのに、このファイルを更新しないとこんなことになります。 大量にログが流れてくるので、原因を特定しにくい感じになります。
app[web.1]: File "/app/.heroku/python/lib/python3.7/site-packages/gunicorn/util.py", line 350, in import_app
app[web.1]: __import__(module)
app[web.1]: File "/app/guardian.py", line 4, in <module>
app[web.1]: import flask_dance.contrib.github
app[web.1]: ModuleNotFoundError: No module named 'flask_dance'
app[web.1]: [2018-11-19 00:00:48 +0000] [13] [INFO] Worker exiting (pid: 13)
app[web.1]: [2018-11-19 00:00:48 +0000] [4] [INFO] Shutting down: Master
app[web.1]: [2018-11-19 00:00:48 +0000] [4] [INFO] Reason: Worker failed to boot.
heroku[web.1]: Process exited with status 3
heroku[web.1]: State changed from up to crashed
heroku[router]: at=error code=H10 desc="App crashed" method=GET path="/" host=python.ms request_id=8d9f8c82-200d-47e2-a366-bceef47e1a79 fwd="61.197.243.235,172.69.135.151" dyno= connect= service= status=503 bytes= protocol=http
ログが色付けされていたエラー文にばかり気を取られて、はまっていました。
よく見たらその少し上に ModuleNotFoundError との文字が見つけ気づくことができました。
落ち着いて読まないとダメやな...
ローカルでは動くのに、Heroku では動かない時はこのケースが多いような気がします。
# (3) Procfile
# 記載
アプリケーションの起動方法を指定します。 これが一番の難所です。
web: uwsgi --http-socket :$PORT --module 'flaskr:create_app()'
以下のような書式です。
web: アプリケーションの起動コマンド
Procfile に関する公式ドキュメントは、こちらになります。
ここでのポイントは --http ではなく --http-socket です。
違いはわかりません。
--httpを Heroku で使っちゃダメだよ。--http-socketを使ってな。
do not use--httpon heroku. Use--http-socket.
uwsgi failing to start on Heroku? - Stackoverflow (opens new window)
この辺りを読んで現在勉強中です。
- 知ったかぶりをしていたソケット通信の基礎を改めて学んでみる - Qiita (opens new window)
- まつもと直伝 プログラミングのオキテ 第16回 ネットワーク・プログラミング(ソケット編) (opens new window)
:$PORT の $PORT は環境変数です。Heroku の環境変数 $PORT には、通信に使用するポートが記載されます。
コロン : の前には本来 IP アドレスが記述されます。
例えば 127.0.0.1:5000 のような書かれ方をします。ここでは省略されています。
あまりよくわかっていません。
uWSGI の公式ドキュメントに Heroku での設定の仕方が書かれていました。
# これをしないとどうなるか
Procfile については、この辺にもまとまっています。 書かなくても動く場合があるらしいです。 ただ、仕組みがぱっと見、不明瞭なので、書いた方が望ましいかな...と。
- Procfileの書き方についてまとめておく - CreepFablic (opens new window)
- Procfileの意味がやっと分かったお話 - CreepFablic (opens new window)
Procfile には頭に web をつけないといけません。
以下、Heroku の公式チュートリアルの文章を引用します。
Define a Procfile - Getting Started on Heroku with Python (opens new window)
あなたがデプロイするサンプルのアプリにある
Procfileの書式は以下のようなものです。
TheProcfilein the example app you deployed looks like this:web: gunicorn gettingstarted.wsgi --log-file - 訳注 gunicorn gettingstarted.wsgi --log-file - コマンドなんて わけわからんちんだと思います。 自分もわけわからんちんです。 意味合いとしては gettingstarted/wsgit.py ファイルの中にある https://github.com/heroku/python-getting-started 変数 application と gunicorn をつないでくださいという意味になります。これは単一のプロセスの
webと、それを実行するのに必要なコマンドを宣言します。
This declares a single process type,web, and the command needed to run it.ここで
webは、重要です。
The namewebis important here.
webと書くと、デプロイされた時に、 このプロセスは Heroku の HTTP routing stack に割り当てられて、 ウェブトラフィックを受信します。
It declares that this process type will be attached to the HTTP routing (opens new window) stack of Heroku, and receive web traffic when deployed.
web 以外もあります。
いろんなコマンドが実行できるけど、
そのうちのコマンドのこれに HTTP の通信を割り当ててね、と言う意味合いになるそうです。
# Step 21. ローカルで動作確認
デプロイする一歩手前まで来ました。 最後にローカルでも動くか再度、確認してみたいと思います。
heroku local コマンドを実行して、ローカルで起動してみてください。
$ heroku local
アクセスする先は http://localhost:5000/ になります。
自分のパソコンで動かなければ、Heroku にあげても動きません。
# Step 22. Heroku にデータベースを追加する。
macOS にデータベースをインストールしたように Heroku にもデータベースを追加します。
$ heroku addons:create heroku-postgresql:hobby-dev
# 確認する。
データベースが追加されているか、確認してください。
$ heroku pg:info
$ heroku pg:info
=== DATABASE_URL
Plan: Hobby-dev
Status: Available
Connections: 0/20
PG Version: 10.6
Created: 2019-02-14 10:19 UTC
Data Size: 8.1 MB
Tables: 4
Rows: 12/10000 (In compliance)
Fork/Follow: Unsupported
Rollback: Unsupported
$
# Step 23. 環境変数の設定
これをいれておいてあげないと、このあと実行する flask init-db が実行できません。
flask コマンドと flaskr アプリを連携させるものです。
$ heroku config:set FLASK_APP="flaskr"
# Step 24. Heroku にデプロイする。
ここで一旦 Heroku にデプロイします。
git add .
git commit -m "initial commit"
git push heroku master
# Step 25. Heroku にテーブルを作成する。
テーブルを作成します。
$ heroku run flask init-db
Heroku に先にデプロイ、すなわち git push heroku master しないと flask init-db コマンドが使えません。
なぜなら git push heroku master した時に pip install flask されるからです。
さらになぜなら flask init-db コマンドは pip install flask しないと使えないコマンドなのです。
# H14 エラーが出ていたら...
もし H14 エラーが出ていた場合、以下のコマンドで復旧する可能性があります。
$ heroku ps:scale web=1
H14 エラーに引っかかりました。以前は引っかからなかったのに、なんでだろう...
- No web processes running Django in heroku - Stackoverflow (opens new window)
- Heroku Error H14 with Django - Vibbu (opens new window)
- heroku上でアプリケーションが起動しないで、ログに「H14 No web process running 」とエラーが出てしまいます。。 (opens new window)
Heroku のコマンド集です。
# 確認する。
これでアクセスして動いているか確認して見ましょう。 Heorku のアプリケーションログ ここに載っている、マジでありがたい。
# おわりに
長い笑 さらに GitHub にコミットすると自動的に Heroku にデプロイしてくれる方法があります。
以上になります。ありがとうございました。