
# timeit ってなに?
正確な実行時間を測りたい時に、実行時間のベンチマークを測りたい時に、使います。 time モジュール, cProfile モジュールに比べて、より正確な値を計測できます。 原理的にはそこまで難しくなく、文字列で渡されたコードを繰り返し実行してその平均値を求めています。
# 1. timeit は、いつ使うの?
答え: OS の time コマンド, time モジュールの結果のばらつきが 気になるようになったら、timeit モジュールの使いどきだと思います。
気にならなければ、無理して timeit を使わず OS の time コマンドや Python の time モジュールでいいかなとも思います。 timeit モジュールは、面倒です。コードを都度、文字列にしないといけないので。
例えば、下記のリンク先の記事では、質問者さんが、そのばらつきを気にしていて、 回答者から timeit を使いなよー。と指摘されています。
- Why is there no xrange function in Python3? (opens new window)
- xrange | Python 2.7.x と 3.x の決定的な違いを例とともに (opens new window)
大きく分けて2つ、「コマンドライン」で計測する方法と、「対話モード」で計測する方法があります。
# 2. コマンドラインで計測
$ python -m timeit "繰り返す処理"
$ # ベタ書き
$ python -m timeit "4 // 3"
100000000 loops, best of 3: 0.0132 usec per loop
このときの実行結果の意味は、 以下のようなものです。
100000000 回の loop を 3 回行って 3 つの平均を求めた。 3 つの平均の最も速かった平均値は 0.0132 usec である。
「最も速かった平均値」を結果として、
提示しているのは恐らく
「他のアプリケーションから最も影響を受けていなかった時の時間」という意味合いかなと思っています。
100000000 は -n オプションで, 3 は -r オプションで、それぞれ指定できます。
指定しない場合は計測の合計時間が 0.2 秒以上になる程度に、 自動的に loop 回数を指定してくれている気配があります。
def autorange(self, callback=None):
"""Return the number of loops and time taken so that total time >= 0.2.
"""
cpython/Lib/timeit.py (opens new window)
# 2.2. 最初に一度だけ実行したい処理がある場合
-s オプションを使います。
$ python -m timeit -s "最初に1度だけ実行する処理" "繰り返す処理
$ # 関数を使って
$ python -m timeit -s "import math" "math.floor(4 / 3)"
10000000 loops, best of 3: 0.169 usec per loop
$
これを使ってそこそこ長い処理でも、自分で定義したスクリプトを import して実行させることができます。
$ python -m timeit -s "import myscript" "myscript.myfunc(123)"
# 2.3. 複数行にわたる場合
次のようにスペースで区切って書きます。
$ python -m timeit "繰り返す処理の1行目" "繰り返す処理の2行目" "繰り返す処理の3行目" ...
$ # list と tuple の生成
$ python -m timeit "[1,2,3]" "[1,2,3]" "[1,2,3]"
10000000 loops, best of 3: 0.18 usec per loop
$ python -m timeit "(1,2,3)" "(1,2,3)" "(1,2,3)"
10000000 loops, best of 3: 0.0221 usec per loop
;セミコロンで
単純文
を繋げることができます。
$ python -m timeit "(1,2,3);(1,2,3);(1,2,3)"
10000000 loops, best of 3: 0.0221 usec per loop
$ python -m timeit "[1,2,3];[1,2,3];[1,2,3]"
10000000 loops, best of 3: 0.181 usec per loop
ただし ;セミコロンでは for 文のような
複合文
は繋げられません。
自分は、何度も弾かれました...
$ python -m timeit "lst = []; for i in range(3000*3000): lst.append(None)"
...
File "<timeit-src>", line 2
lst = []; for i in range(3000*3000): lst.append(None)
^
SyntaxError: invalid syntax
Why can't use semi-colon before for loop in Python? (opens new window)
# 3. 対話モードで計測
# 3.1. 文字列を渡す
複数行にわたる場合は、次のようにスクリプト内で文字列にして timeit 関数に渡すような書き方もできます。
>>> import timeit
>>> stmt = """\
繰り返す処理の1行目
繰り返す処理の2行目
繰り返す処理の3行目
...
"""
>>>
>>> # 1,000,000 回実行した総実行時間
>>> timeit.timeit(stmt)
11.8873
>>>
ソースコードを確認してみると、スクリプト内で実行された場合は 「1000000 回実行した回数の総合計時間を秒単位で返している」ようです。 実際にそうなのか time.sleep 関数を使って確認して見ました。
#
# 1 に近い値が返されていれば想定通り
#
import timeit
timeit.timeit("time.sleep(1/1)", "import time", number=1)
timeit.timeit("time.sleep(1/10)", "import time", number=10)
timeit.timeit("time.sleep(1/100)", "import time", number=100)
timeit.timeit("time.sleep(1/1000)", "import time", number=1000)
timeit.timeit("time.sleep(1/10000)", "import time", number=10000)
timeit.timeit("time.sleep(1/100000)", "import time", number=100000)
timeit.timeit("time.sleep(1/1000000)", "import time", number=1000000)
timeit.timeit("time.sleep(1/1000000)", "import time")
timeit.default_number # 1000000
>>> import timeit
>>>
>>> timeit.timeit("time.sleep(1/1)", "import time", number=1)
1.0048440069999884
>>> timeit.timeit("time.sleep(1/10)", "import time", number=10)
1.0244071230000031
>>> timeit.timeit("time.sleep(1/100)", "import time", number=100)
1.1111561590000036
>>> timeit.timeit("time.sleep(1/1000)", "import time", number=1000)
1.2499619090000067
>>> timeit.timeit("time.sleep(1/10000)", "import time", number=10000)
1.715848617000006
>>> timeit.timeit("time.sleep(1/100000)", "import time", number=100000)
5.096340972000007
>>> timeit.timeit("time.sleep(1/1000000)", "import time", number=1000000)
9.260918925000624
>>> timeit.timeit("time.sleep(1/1000000)", "import time")
11.693422654999999
>>>
>>> timeit.default_number
1000000
>>>
後半は、大きく値がブレます.. 大体は理解は、あっているとは思うのですが、うーん、ちょっと怪しい。
pythonのベンチマーク用モジュールtimeitの使い方と落とし穴。 (opens new window)
# 3.2. 名前空間を渡す
文字列で渡すのは面倒なので、名前空間をそのまま渡す方法が公式ドキュメントにありました。
他のオプションは globals() を globals 引数に渡すことです。 これによりコードはあなたのグローバル名前空間内で実行されます。 これはそれぞれでインポートするより 便利です:
27.5. timeit — 小さなコード断片の実行時間計測 (opens new window)
def f(x):
return x**2
def g(x):
return x**4
def h(x):
return x**8
import timeit
print(timeit.timeit('[func(42) for func in (f,g,h)]', globals=globals()))
# 4. 用語
# 4.1. ベンチマーク
timeit はベンチマークを取得するのに適しています。反対に cProfile はベンチマークを取得するのに適していません。
注釈: 2つのプロファイラモジュールは、与えられたプログラムの実行時プロファイルを取得するために設計されており、 ベンチマークのためのものではありません (ベンチマーク用途には timeit のほうが正確な計測結果を求められます)。 27.4. Python プロファイラ (opens new window)
なので、timeit ではより正確な時間を計測するために、わざわざ複数回の試行を 3 回も繰り返し、その3回の中でもっとも速かった時間を、 他のプログラムの影響を受けていなかった正確な時間であるとして、提示しています。
ある特定の機能を果たすプログラムを書くときに複数の手法が存在した場合、どの手法が最も効率的かを知る上でベンチマークを取る。
プログラミング作業におけるベンチマーク | Wikipedia (opens new window)
# 4.2. プロファイル
プロファイルは、関数ごとの時間を計測したものです。どこが遅いかを調べるときに計測します。 これについては、次の記事で「cProfile でプロファイリング」でご紹介したします。
# 4.3. コマンドライン
ここのサイトは、いつも分かり易すぎて感動します。
コマンドライン (command line) (opens new window)
-m オプションの詳細については 「import 文ってなに?」 の中でご紹介させていただきました。
パスを理解する必要があったりするので、すこし長い旅に出る必要があります。
1. コマンドラインと環境 - Python のセットアップと利用 (opens new window)
-m <module-name>
sys.path から指定されたモジュール名のモジュールを探し、その内容を __main__ モジュールとして実行します。 引数は module 名なので、拡張子 (.py) を含めてはいけません。
# 4.4. 対話モード
はじめて、対話モードって言葉を知りました笑
2.1.2. 対話モード - Python チュートリアル (opens new window)
インタプリタが命令を端末 (tty) やコマンドプロンプトから読み取っている場合、 インタプリタは 対話モード (interactive mode) で動作しているといいます。 このモードでは、インタプリタは 一次プロンプト (primary prompt) を表示して、 ユーザにコマンドを入力するよう促します。
# 5. timeit の注意事項
timeit に定数を渡すと「定数畳み込み」という最適化を施されて計算が前もって実行されてしまいます。 とりあえず、どういうことが起こるかをまず示します。
# 5.1. 割り算
組み込み関数 divmod と四則演算子 //, % のベタ書き、 どちらが速いか比べてみます。
### コマンドラインに
### 実際にコピペして比べて見てください。
## OK
# OK a
python3 -m timeit -s "a,b=5,3" "divmod(a,b)"
# OK b
python3 -m timeit -s "a,b=5,3" "a//b,a%b"
## NG
# NG a
python3 -m timeit "divmod(5,3)"
# NG b
python3 -m timeit "5//3,5%3"
# NG c
# NG b は NG c と結果が一緒になる。
python3 -m timeit "1,2"
$ ### コマンドラインに
$ ### 実際にコピペして比べて見てください。
$ ## OK
$ # OK a
$ python3 -m timeit -s "a,b=5,3" "divmod(a,b)"
2000000 loops, best of 5: 134 nsec per loop
$
$ # OK b
$ python3 -m timeit -s "a,b=5,3" "a//b,a%b"
5000000 loops, best of 5: 88 nsec per loop
$
$
$ ## NG
$ # NG a
$ python3 -m timeit "divmod(5,3)"
2000000 loops, best of 5: 131 nsec per loop
$
$ # NG b
$ python3 -m timeit "5//3,5%3"
50000000 loops, best of 5: 9.5 nsec per loop
$
$ # NG c
$ # NG b は NG c と結果が一緒になる。
$ python3 -m timeit "1,2"
50000000 loops, best of 5: 9.67 nsec per loop
$
# 5.2. 一次元リストと二次元リスト
「二次元リスト」と「一次元リスト(二次元リストを表現したもの)」を 比較してみたいと思います。 これは競技プログラミングのコードを見ていた時に出てきたコードです。 C 言語の場合は一次元リスト(正確にはリストではなく配列)でやったほうが速いらしいです。 Python では、どうでしょうか?
# OK a
python -m timeit -s "lst=[None]*3000*3000;row=1500;col=1500;N=3000" "lst[row*N+col]"
# OK b
python -m timeit -s "lst=[[None]*3000 for i in range(3000)];row=1500;col=1500" "lst[row][col]"
# NG a
python -m timeit -s "lst=[None]*3000*3000" "lst[1500*3000+1500]"
# NG b
python -m timeit -s "lst=[[None]*3000 for i in range(3000)]" "lst[1500][1500]"
# NG c
# NG c は NG a と同じ結果になる。
python -m timeit -s "lst=[None]*3000*3000" "lst[4501500]"
$ # OK a
$ python -m timeit -s "lst=[None]*3000*3000;row=1500;col=1500;N=3000" "lst[row*N+col]"
2000000 loops, best of 5: 109 nsec per loop
$
$ # OK b
$ python -m timeit -s "lst=[[None]*3000 for i in range(3000)];row=1500;col=1500" "lst[row][col]"
5000000 loops, best of 5: 77 nsec per loop
$
$ # NG a
$ python -m timeit -s "lst=[None]*3000*3000" "lst[1500*3000+1500]"
10000000 loops, best of 5: 34 nsec per loop
$
$ # NG b
$ python -m timeit -s "lst=[[None]*3000 for i in range(3000)]" "lst[1500][1500]"
5000000 loops, best of 5: 69.6 nsec per loop
$
$ # NG c
$ # NG c は NG a と同じ結果になる。
$ python -m timeit -s "lst=[None]*3000*3000" "lst[4501500]"
10000000 loops, best of 5: 33.9 nsec per loop
$
# 5.3. どうしてこうなった?
答え: timeit はバイトコンパイルされたコードを実行しているから。
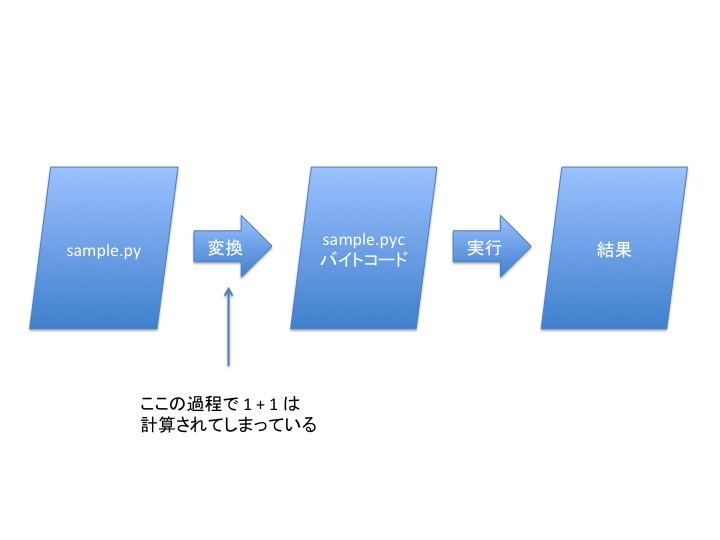
実は Python はコンパイルを行ない、 バイトコードへ変換しています。 CPython は、このバイトコード読み込んで処理を実行しています。
バイトコードに変換される段階で、 1 + 1 = 2 が実行されていたと言うことです。 このような最適化を 定数畳み込み (opens new window) と言うらしいです。ちなみに僕はバイトコードを、ほとんど理解していません。
timeit では、複数回処理を実行してその平均値を返してくれますが、 バイトコードへの変換は1度しか行っていません。 この後、実際に timeit のコードを覗いて見て、 バイトコンパイルしている箇所をご紹介いたします。
# 5.4. バイトコード
バイトコードをサクッと見てみたいと思います。 標準ライブラリの dis を使うことでバイトコンパイルされた コードを覗くことができます。
import dis
OK = """
a, b = 5, 3
a // b, a % b
"""
NG = """
5 // 3, 5 % 3
"""
dis.dis(OK)
dis.dis(NG)
>>> dis.dis(OK)
2 0 LOAD_CONST 0 ((5, 3))
2 UNPACK_SEQUENCE 2
4 STORE_NAME 0 (a)
6 STORE_NAME 1 (b)
3 8 LOAD_NAME 0 (a)
10 LOAD_NAME 1 (b)
12 BINARY_FLOOR_DIVIDE
14 LOAD_NAME 0 (a)
16 LOAD_NAME 1 (b)
18 BINARY_MODULO
20 BUILD_TUPLE 2
22 POP_TOP
24 LOAD_CONST 1 (None)
26 RETURN_VALUE
>>> dis.dis(NG)
2 0 LOAD_CONST 0 ((1, 2))
2 RETURN_VALUE
>>>
おわかりいただけただろうか? ワイはあんまりバイトコードを、わかってない。 OK はちゃんと割り算っぽいことをしていそうなのに、 NG は 1, 2 をそのまま返してしまっています。
英語ですがアメリカの PyCon でバイトコードについて 解説してくれている動画がありました。 PyCon というのは毎年開催される Python 祭りです。
# 6. timeit の仕組み
timeit はざっくり文字列で与えられたコードを繰り返し実行して、 その時間を time.perf_counter 関数で計測します。 そこまで複雑なことはしていなさそうです。
template = """
def inner(_it, _timer{init}):
{setup}
_t0 = _timer()
for _i in _it:
{stmt}
_t1 = _timer()
return _t1 - _t0
"""
template という変数に文字列で変換されたコードが、 繰り返し for 文で実行されてるなーというのをなんとなく覚えておいてください。
文字列で渡して for 文で繰り返し実行するだけのようです。 だから、わざわざあんなに面倒な、コードを文字列にして渡すなんてことをしないといけなかったんですね。
timeit の it は英語の iterate, 繰り返すの略だと思われます。 繰り返し何回も計測して正確な値を計測するという意味合いかと思われます。
ここでは、標準ライブラリ timeit が コマンドラインから実行された場合のコードを 追いかけてみたいと思います。
$ python -m timeit "[i for i in range(10)]"
500000 loops, best of 5: 910 nsec per loop
$
「標準ライブラリのコードを読む」というコンセプトでやっているので、 ざっくりてきとーに眺めていただけると嬉しいです。 基本的に伝えたいことは以下の3点だけです。
- timeit は、文字列のコードを for 文で繰り返しているだけ
- 最適化フラグを on にしてバイトコンパイルしている
- ガベレージコレクションを無効にしている
# 6.1. 起動
スクリプトとして実行されるとき
__name__ には __main__ が代入されます。
main 関数が実行されるようです。
if __name__ == "__main__":
sys.exit(main())
# 6.2. main 関数(1) 繰り返し回数の決定
コードの中に "# determine number so that 0.2 <= total time < 2.0" というコメントがありました。
def main(args=None, *, _wrap_timer=None):
...
if number == 0:
# determine number so that 0.2 <= total time < 2.0
...
繰り返しの回数 number は、総合計時間が 0.2 秒以上 2 秒以下になるように autorange メソッドを使って計算しているようです。
def main(args=None, *, _wrap_timer=None):
...
number, _ = t.autorange(callback)
...
# 6.3. main 関数(2) 準備
Timer オブジェクトを生成します。 実際の計測には標準ライブラリ time の perf_counter を使っているのが見えます。
...
default_timer = time.perf_counter
...
def main(args=None, *, _wrap_timer=None):
...
timer = default_timer
...
t = Timer(stmt, setup, timer)
...
Timer オブジェクトは計測対象の文字列で渡されたコードを バイトコードに変換して保持します。 template に format メソッドで計測対象の文字列 stmt を代入しているのが見えます。
class Timer:
def __init__(self, stmt="pass", setup="pass", timer=default_timer,
globals=None):
...
src = template.format(stmt=stmt, setup=setup, init=init)
self.src = src # Save for traceback display
# 最適化フラグ -O を有効にしたのと同じ状態で
# 関数 inner をバイトコードにコンパイルしています。
code = compile(src, dummy_src_name, "exec")
# この exec は
# 関数 を実行 exec しているのではなく
# 関数の定義を実行 exec しています。
exec(code, global_ns, local_ns)
# 定義した関数を属性に代入する。
self.inner = local_ns["inner"]
compile(source, filename, mode, flags=0, dont_inherit=False, optimize=-1)
source を コードオブジェクト 、もしくは、 AST オブジェクトにコンパイルします。... 中略 ...
引数 optimize は、コンパイラの最適化レベルを指定します; デフォルトの値 -1 は、インタプリタの -O オプションで与えられるのと同じ最適化レベルを選びます。 明示的なレベルは、 0 (最適化なし、 __debug__ は真)、 1 (assert は取り除かれ、 __debug__ は偽)、 2 (docstring も取り除かれる) です。
2. 組み込み関数 - Python 標準ライブラリ (opens new window)
コードオブジェクト
コードオブジェクトはバイトコンパイルされた (byte-compiled) 実行可能な Python コード、別名 バイトコード (bytecode) を表現します。
内部型 - Python 言語リファレンス (opens new window)
なんだか文字列でコードを実行させたり、コンパイルしたり回りくどいですね。 正確に計測するための工夫らしいです。
このモジュールは、実行時間を計測するにあたって、いくつものよくある罠を回避しています。 オライリーから刊行されている Python Cookbook の中にある、 Tim Peter が書いたアルゴリズムの章の "はじめに" を参考にしてください。
This module avoids a number of common traps for measuring execution times. See also Tim Peters' introduction to the Algorithms chapter in the Python Cookbook, published by O'Reilly.
cpython/Lib/timeit.py (opens new window)
# 6.4. main 関数(3) ループの実行
raw_timings に number 回のループを repat 回実行した結果を保存します。 そして min 関数で最小値、すなわち最も速かった実行結果を取得します。
...
default_repeat = 5
...
def main(args=None, *, _wrap_timer=None):
...
repeat = default_repeat
...
try:
raw_timings = t.repeat(repeat, number)
...
timings = [dt / number for dt in raw_timings]
best = min(timings)
...
5.3, 5.4. の全体像は以下のようなものです。
...
default_timer = time.perf_counter
default_repeat = 5
...
def main(args=None, *, _wrap_timer=None):
...
timer = default_timer
...
repeat = default_repeat
...
t = Timer(stmt, setup, timer)
...
try:
raw_timings = t.repeat(repeat, number)
except:
t.print_exc()
return 1
...
timings = [dt / number for dt in raw_timings]
best = min(timings)
...
# 6.5. Timer.repeat メソッド
Timer.repeat メソッドは純粋に Timer.timeit メソッドを繰り返し実行しているだけのようです。
class Timer:
def repeat(self, repeat=default_repeat, number=default_number):
...
r = []
for i in range(repeat):
t = self.timeit(number)
r.append(t)
return r
# 5.6. Timer.timeit メソッド
ここで注目していただきたいのは、 gc.disable を呼び出してガベレージコレクションを無効にしていることです。 なぜガベレージコレクションを計測に当たって無効にしているのか、 その理由はわかりません。
class Timer:
def timeit(self, number=default_number):
...
it = itertools.repeat(None, number)
gcold = gc.isenabled()
gc.disable()
try:
timing = self.inner(it, self.timer)
finally:
if gcold:
gc.enable()
return timing
# 7. まとめ
ここまで以下のように見てきました。
timeit の使い方と中身をざっくりと見てきました。 正確な計測を行うために、繰り返し計測するといったこと以外にも、計測前にガベレージコレクションを無効にしたり、 計測前に最適化オプションを有効にしてバイトコードにコンパイルしたりといった工夫も行われていました。