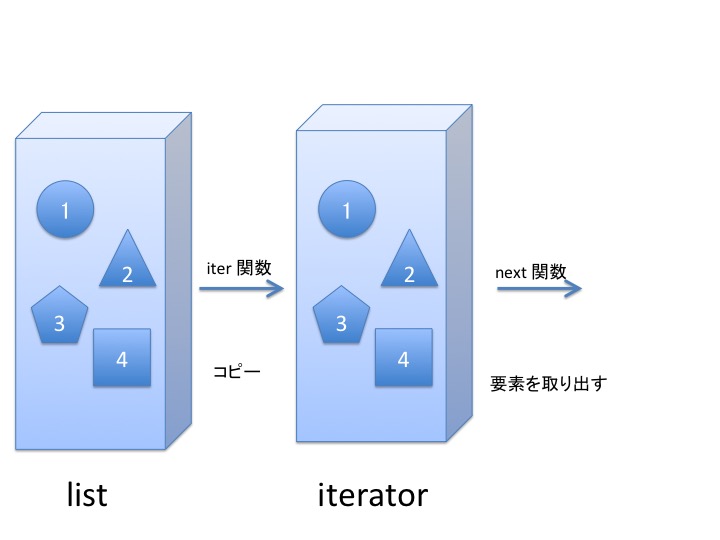
イテレータってなに?
リストのコピーみたいなものです。
#
# 対話モード >>> に
# コピペしてみてください。
#
from time import sleep
def ジェネレータ関数():
while True:
for _ in range(14):
yield '(・ω・\)SAN値!'
sleep(0.3)
yield '(/・ω・)/ピンチ!'
sleep(0.5)
yield '\(・ω・\) SAN値! (/・ω・)/'
sleep(0.3)
yield 'ハァ!'
sleep(0.5)
ジェネレータイテレータ = ジェネレータ関数()
for 要素 in ジェネレータイテレータ:
print(要素)
メリットは...
デメリットは...
リストを返してくれる関数について考えたいと思います。 標準ライブラリ itertools の中に accumulate 関数 (opens new window) という、累積和を返してくれる簡単な関数があります。
#
# 対話モード >>> に
# コピペで実行できます。
#
from itertools import accumulate
lst = accumulate((1, 2, 3, 4, 5))
for e in lst:
print(e)
# 1
# 3
# 6
# 10
# 15
リストを使ったものとジェネレータを使ったものを、 それぞれ実装して比較してみたいと思います。
#
# 対話モード >>> に
# コピペで実行できます。
#
# リストを返す関数
def accumulate_list(iterable):
current = 0
lst = []
for element in iterable:
current += element
lst.append(current)
return lst
# リスト
lst = accumulate_list((1, 2, 3, 4, 5))
for e in lst:
print(e)
# 1
# 3
# 6
# 10
# 15
yiled 文を使った関数定義文を ジェネレータ関数 と言います。 ジェネレータ関数が返すオブジェクトを ジェネレータイテレータ と言います。
#
# 対話モード >>> に
# コピペで実行できます。
#
# ジェネレータ関数
def accumulate_generator(iterable):
current = 0
for element in iterable:
current += element
yield current
# ジェネレータイテレータ
gen = accumulate_generator((1, 2, 3, 4, 5))
for e in gen:
print(e)
# 1
# 3
# 6
# 10
# 15
リスト lst と ジェネレータイテレータ gen は、 まったく同じ動作をしているように見えます。違いは何でしょうか?
答え: 要素を生成するタイミングが違います。
for 文は要素を1つずつ取り出してくれます。
リストは、for loop が実行される前に、全ての要素を生成します。 それに対してジェネレータイテレータは、 for loop が回るたびに、処理を起動をして要素を生成し、要素を渡したら処理を中断しています。
このようにして、必要になるまで処理を実行しないことを遅延評価と言います。 遅延評価のため、ジェネレータは for 文や next 関数 (opens new window) を使って1つ1つ要素を取り出すことはできますが...
gen = accumulate_generator(range(10))
next(gen) # 0
next(gen) # 1
next(gen) # 3
next(gen) # 6
next(gen) # 10
next(gen) # 15
next(gen) # 21
next(gen) # 28
next(gen) # 36
next(gen) # 45
next(gen) # StopIteration
反対に、いきなり途中の要素、 例えばいきなり 5 番目の要素を取り出すというようなことはできません。
lst = accumulate_list(range(10))
lst[5]
gen = accumulate_generator(range(10))
gen[5] # TypeError
また next 関数によって次の要素を取り出すことはできますが、 1つ前の要素を取り出すと言ったこともできません。
リストは全ての要素を生成してしまうので、大量のメモリを消費してしまいます。 ジェネレータイテレータは、必要なものしか作らないので、そうでもありません。
int 型くらいならいいかもしれませんが、ファイルなど大量の str 型を扱う場合には、 意識しないといけないことになります。
import sys
# メモリを大量消費(実行に時間がかかります。)
sys.getsizeof(accumulate_list(range(10**8)))
# 859724472
# メモリをあまり消費しない
sys.getsizeof(accumulate_generator(range(10**8)))
# 88
sys.getsizeof(object[, default]) (opens new window)
オブジェクトのサイズをバイト単位で返します。オブジェクトは、どのような型でも使えます。 組み込み型は、正しい結果を返してくれますが、 サードパーティ製の型は、正しい結果を返してくれるとは限らず、実装によって異なるかもしれません。 属性に直接代入されたオブジェクトが消費したメモリだけ計測され、 属性の属性に代入されたオブジェクトが消費するメモリについてまでは計測しません 。
Return the size of an object in bytes. The object can be any type of object. All built-in objects will return correct results, but this does not have to hold true for third-party extensions as it is implementation specific. Only the memory consumption directly attributed to the object is accounted for, not the memory consumption of objects it refers to.
ジェネレータイテレータは、リストではありません。 デメリットは、リストのように途中の値を参照することはできず、すこし使い勝手が悪いです。 メリットはメモリの消費量を抑えることができます。 大量のオブジェクトを取り扱う時に威力を発揮します。
ジェネレータイテレータをリストと比較したとき、 ジェネレータイテレータのメリットとして正しいものは次のうちどれですか?
リストを返す簡易的な表記がリスト内包表記なら、 ジェネレータイテレータを返す簡易的な表記がジェネレータ式です。
# リスト
lst = [i for i in range(10)]
def f():
lst = []
for i in range(10):
lst.append(i)
return lst
assert lst == f()
# ジェネレータ
gen = (i for i in range(10))
def g():
for i in range(10):
yield i
assert list(gen) == list(g())
イテラブルを1つだけ引数に取る関数には、 ジェネレータ式をそのまま書き込むことができます。 イテラブルというのは for 文の in の中に書き込める オブジェクトないしそのクラスのことです。 例えば range, list, tuple が該当します。 ここでご紹介させていただいているジェネレータも イテラブルになります。
sum(i for i in range(10))
# 二重の括弧はいらない
# sum((i for i in range(10)))
答え: 基本的にはジェネレータかな...
答え: Python 2 では list を返す関数だった zip, range, map, filter が Python 3 ではイテレータクラスに変更されたから
Python の開発者の人たちの意図としては、基本的にはリストよりもイテレータを使いましょうね。という雰囲気なのかなと思っています。 メモリの消費というのがクリティカルだったのかなと思います。
また、書籍 Effective Python の項目 16 でも「リストを返さずにジェネレータを返すことを考える」と書かれています。
もう1度、メリットデメリットを再確認してみます。 (1), (3) はご説明させていただいたので省略して、 ここでは (2), (4) だけ触れます。
| 番号 | 項目 | ジェネレータ | リスト |
|---|---|---|---|
| (1) | メモリ | 殆ど消費しない | 要素数分消費する |
| (2) | 書きやすさ | list の初期化不要 | list の初期が必要 |
| (3) | 扱いやすさ | 次の要素だけ参照可 | どこでも参照可 |
| (4) | 速度 | ごく若干遅い | ごく若干速い |
ほんの、ほんのちょっとだけ短くなります。
# リストを返す関数
def accumulate_list(iterable):
current = 0
lst = [] # <- 余分な1行
for element in iterable:
current += element
lst.append(current) # <- append って書かないといけない
return lst
# ジェネレータ関数
def accumulate_generator(iterable):
current = 0
for element in iterable:
current += element
yield current
実は速度は、ほんの、ほんのすこしだけリストが速そうです。 計測したコードを示すことはできないのですが、感覚だけお伝えします。 しかし、本当にほんのちょっとだけです。
ジェネレータ式で書いても、リスト内包表記で書いても、 どちらでもいい場合は、どちらで書くのが望ましいでしょうか?
実は、ジェネレータイテレータは、1度 for 文で回すと空になります。 このことに引っかかって、時間を費やしてしまった方を Twitter や Qiita でたまに見かけます。
実際に見てましょう。
# コピペで実行できます。
def accumulate_generator(iterable):
current = 0
for element in iterable:
current += element
yield current
gen = accumulate_generator(range(10))
for e in gen: e
# 0, 1, 3, 6, 10, 15, 21, 28, 36, 45
for e in gen: e
# 2回目は、何も表示されない
驚いたことに、ジェネレータの戻り値に ... 何も結果が得られません。... この振る舞いの原因は、イテレータが結果を一度だけしか生成しないことです。... 紛らわしいのは、すでに尽きてしまったイテレータに対して反復処理をしても、何のエラーも生じないことです。
項目17: 引数に対してイテレータを使うときには... - Effective Python (opens new window)
なぜ、このようなことが起こるのでしょうか? それはジェネレータイテレータがイテレータだからです。 この原因の詳細は、このあと「イテレータってなに?」の中で説明させていただきます。
とりあえず対応策だけ知りたい方は、こちらからどうぞ。3つの対応策を示しています。
# コピペで実行できます。
# 対応策 1 再度呼び出す
def accumulate_generator(iterable):
current = 0
for element in iterable:
current += element
yield current
gen = accumulate_generator(range(10))
for e in gen: e
# 0, 1, 3, 6, 10, 15, 21, 28, 36, 45
gen = accumulate_generator(range(10))
for e in gen: e
# 0, 1, 3, 6, 10, 15, 21, 28, 36, 45
# コピペで実行できます。
# 対応策 2 リストにする。
def accumulate_generator(iterable):
current = 0
for element in iterable:
current += element
yield current
gen = accumulate_generator(range(10))
lst = list(gen)
for e in lst: e
# 0, 1, 3, 6, 10, 15, 21, 28, 36, 45
for e in lst: e
# 0, 1, 3, 6, 10, 15, 21, 28, 36, 45
# コピペで実行できます。
# 対応策 3 コンテナクラスを作る
# 3つ目の対策の詳細は
# 「イテレータってなに?」でご説明いたします。
def accumulate_generator(iterable):
current = 0
for element in iterable:
current += element
yield current
class AccumulateGenerator:
def __init__(self, iterable):
self._iterable = iterable
def __iter__(self):
return accumulate_generator(self._iterable)
gen = AccumulateGenerator(range(10))
for e in gen: e
# 0, 1, 3, 6, 10, 15, 21, 28, 36, 45
for e in gen: e
# 0, 1, 3, 6, 10, 15, 21, 28, 36, 45
ジェネレータという言葉には、実は2つの意味があります。区別しましょう。
generator(ジェネレータ) (opens new window)
通常は ジェネレータ関数 を指しますが、文脈によっては ジェネレータイテレータ を指す場合があります。 意図された意味が明らかでない場合、 明瞭化のために完全な単語を使用します。
ジェネレータ関数 (generator function) (opens new window)
yield 文 (yield 文 の節を参照) を使う関数もしくはメソッドを ジェネレータ関数 と呼びます。 そのような関数が呼び出されたときは常に、関数の本体を実行するのに使えるイテレータオブジェクトを返します: イテレータの iterator.__next__() メソッドを呼び出すと、 yield 文を使って値が提供されるまで関数を実行します。 関数の return 文を実行するか終端に達したときは、 StopIteration 例外が送出され、イテレータが返すべき値の最後まで到達しています。
generator iterator(ジェネレータイテレータ) (opens new window)
generator 関数で生成されるオブジェクトです。 yield のたびに局所実行状態 (局所変数や未処理の try 文などを含む) を記憶して、処理は一時的に中断されます。 ジェネレータイテレータ が再開されると、中断した箇所を取得します (通常の関数が実行の度に新たな状態から開始するのと対照的です) 。
「ジェネレータ」という言葉に「含まれない」意味は次のうちどれでしょうか?
Guido van Rossum はジェネレータ関数について、普通の関数を定義する def とは別の用語を、例えば gen のような語を定義しようか迷ったそうです。 何故なら、ジェネレータ関数と普通の関数は、異なるものだからです。それは次の2点です。
1つ目は、関数は return で1度に全ての返り値を評価して返すのに対して、ジェネレータ関数は yeild で返り値を個々に遅延評価して返します。
2つ目は、関数は return で指定されたオブジェクトそのものを返すのに対して、 ジェネレータ関数は yield で指定されたオブジェクトを返すジェネレータイテレータを返します。
最終的には Guido は、自分の直感に従ったそうです。PEP 255 の文章を引用します。 ここで 慈悲深き終身独裁官 (opens new window) とは Guido を指しています。
慈悲深き終身独裁官による判決 - PEP 255 Simple Generators (opens new window)
BDFL Pronouncements - PEP 255 Simple Generators議論
issue
ジェネレータ関数をジェネレータでない関数と区別するために def の代わりに gen や generator のような別の新しいキーワードを導入するか、 あるいは構文を変えるべきかどうか。
Introduce another new keyword (say, gen or generator) in place of def, or otherwise alter the syntax, to distinguish generator-functions from non-generator functions.欠点
con
実際には(あなたがジェネレータをどのように考えているかという観点から言えば)、 ジェネレータは関数である。再開可能であるという差異はあるが。ジェネレータがどのように始動するかという動作原理は、比較的些細な技術的問題である。 新しいキーワードの導入は、ジェネレータがどのように起動するかという動作原理を過度に強調してしまう (起動に関する動作原理は、重要ではあるがジェネレータ全体の動作から見れば小さい)。
In practice (how you think about them), generators are functions, but with the twist that they're resumable. The mechanics of how they're set up is a comparatively minor technical issue, and introducing a new keyword would unhelpfully overemphasize the mechanics of how generators get started (a vital but tiny part of a generator's life).利点
pro
現実には(あなたがジェネレータをどう考えてるかという観点から言えば)、 ジェネレー関数は、実際、ファクトリー関数である。この関数は、関数の動作から考えれば あたかも魔法を使ったように、ジェネレータ関数はジェネレータイテレータを生成している。この観点から言えば、 ジェネレータでない関数とは根本的に違う。関数というよりもむしろ、コンストラクタのように振舞っている。 本文に埋め込まれた yield 文だけでは、意味的に全く違うことを示すには不十分である。
In reality (how you think about them), generator-functions are actually factory functions that produce generator-iterators as if by magic. In this respect they're radically different from non-generator functions, acting more like a constructor than a function, so reusing def is at best confusing. A yield statement buried in the body is not enough warning that the semantics are so different.慈悲深き終身独裁官
BDFL
私の直感はdefと言った。どちらの主張についても完全に納得がいくようなものがない。 そのため、私は自分の言語設計者としての直感に相談することにした。
defit stays. No argument on either side is totally convincing, so I have consulted my language designer's intuition.私の直感は、「PEP で提案されている構文は、まさに的確である - 暑すぎず寒すぎず、ちょうど良い」と教えてくれた。 しかしギリシャ神話のデルポイのご神託のように、なぜそうなのか理由は説明はしてくれない。 なので、私は PEP で提案された構文にについての議論に対して、反証するものを持っていない。
It tells me that the syntax proposed in the PEP is exactly right - not too hot, not too cold. But, like the Oracle at Delphi in Greek mythology, it doesn't tell me why, so I don't have a rebuttal for the arguments against the PEP syntax.最も思いついたものは "恐怖と不安と疑念" (opens new window) である (既に反証がないということに関して同意したことは、さておき)。 もし、ある日から、これが言語の一部になったら、 私は Andrew Kuchling の "Python の嫌なところ" (opens new window) に 掲載されのではないかと、ひどく疑問に感じる。
The best I can come up with (apart from agreeing with the rebuttals ... already made) is "FUD". If this had been part of the language from day one, I very much doubt it would have made Andrew Kuchling's "Python Warts" page.
このことは以下の Qiita の記事から知りました。
全然どうでもいいのですが BDFL Pronouncements って Senatus consultum ultimum みたいな感じがしてカッコいい...
再帰呼び出しでリストを生成する関数をジェネレータ関数に書きかえることを考えます。
リストを生成する関数は、ジェネレータ関数で簡単に表現できました。
しかし、再帰呼び出しでリストを生成する関数を、
そのまま単純に yiledを当てはめてもうまく動作しません。
そのようなケースでは yield from を使います。
二分探索木とは、左に自分より小さな値、右に大きな値を配置したデータ構造です(Wikipedia 調べ)。

二分探索木については、以下の記事で説明させていただきました。
再帰呼び出しを使えば、下図のような二分探索木から、 ソートされたリストをとても簡単に生成することができることができます。
class BinarySearchTree:
# 1) リストを返す関数を
def list(self):
left = self.left.list() if self.left else []
center = [self.value]
right = self.right.list() if self.right else []
return left + center + right
# 2) ジェネレータイテレータを返す関数で書き換え
def __iter__(self):
if self.left:
yield from self.left
yield self.value
if self.right:
yield from self.right
特殊メソッド __iter__ を定義すると list(obj) とした時にリストが得られます。
bst = BinarySearchNode(0)
bst.list() == list(bst)
# True
なにを言ってるかさっぱりだと思います。 イテレータについては、この先のイテレータってなに?でご紹介させていただきます。
ジェネレータ関数から別のジェネレータ関数を呼び出したいとします。 単純に yield を使って呼び出してみます。
# コピペで動きます。
def f():
yield g1()
yield g2()
def g1():
yield 0
yield 1
def g2():
yield 2
yield 3
[i for i in f()]
# [<generator object g1 at 0x100e9db48>, <generator object g2 at 0x100e9dba0>]
yield from を使うと上手くいきます。
# コピペで動きます。
def f():
yield from g1()
yield from g2()
def g1():
yield 0
yield 1
def g2():
yield 2
yield 3
[i recursive.pyfor i in f()]
# [0, 1, 2, 3]
yield from は、処理を subgenerator 子ジェネレータに処理を deligate 移譲しています。
yield from は PEP 380 で Python 3.3 から採用されました。
ここまで以下のように見てきました。
ジェネレータイテレータは、リストを表現してくれています。 しかも実際にリストを生成することなく。 これによってメモリの使用料を削減することができます。 つぎの2つのことを区別します。
| 1. | リストを返す関数 | ジェネレータ関数 |
| 2. | リスト内包表記 | ジェネレータ式 |
ジェネレータという言葉は、ときと場合によって、ジェネレータイテレータであったり、 ジェネレータ関数であったりします。つぎの1つのことを区別します。
| 3. | ジェネレータイテレータ | ジェネレータ関数 |
ジェネレータイテレータは、イテレータの一種です。 次はより汎用的な概念であるイテレータを見ていきます。