

コピーってなに?
二種類あります。浅いコピーと深いコピーです。
例えば、要素数10個のオブジェクトを初期化する場合、 リスト内包表記がオススメです。
lst = [None for _ in range(10)]
また10X10の二次元リストの初期化をする場合は、 次のような具合です。
lst = [[None for _ in range(10)] for _ in range(10)]
他にもやり方はあるのですが、 このやり方をしていれば、 沼に嵌らないからです。
for 文を使ってリストを作ることはよくあります。
lst = []
for _ in range(10):
lst.append(None)
そのようなよくやる操作には簡単な書き方が用意されています。 それがリスト内包表記です。
lst = [None for _ in range(10)]
簡単に書ける構文を、難しい言葉で 「糖衣構文」 (opens new window) と言います。 ただし糖衣構文は、複雑なものには使えないので、簡単なものだけに使うといいかなと思います。
リストの内包
シンプルなケースの場合のみ利用する。
欠点: 複雑なリスト内包表記やジェネレータ式は可読性が低くなります。
Google Python スタイルガイド (opens new window)
リストの中身が int, str, None など
変更できない
オブジェクトの場合、
掛け算 * を使うことをお勧めします。
なぜならこちらの方が速度がいくらか速く、そして簡潔に書けるからです。
# 変更できないオブジェクトの場合
lst = [None] * 20
# 変更できるオブジェクトの場合
lst = [[] for _ in range(20)]
速度の比較は、こちらで行いました。
上記のことをまとめると None で10X10の二次元リストを初期化する場合は、 以下のようになります。
lst = [[None] * 10 for _ in range(10)]
# 解説
lst = [[None] * 10 for _ in range(10)]
# ^^^^^ None は変更できないので、掛け算
lst = [[None] * 10 for _ in range(10)]
# ^^^^^^^^^^^ しかし None が 10 個入ったリストは
# 変更できるので、リスト内包表記
なぜ、このように使い分けるのでしょうか?
二次元リストを作ることを考えます。 変更できるリストのようなオブジェクトの場合、 次のような事故が起こってしまいます。
# やったらダメな例
lst = [[None] * 3] * 3
lst[0][0] = 'Hello'
[id(e) for e in lst]
lst
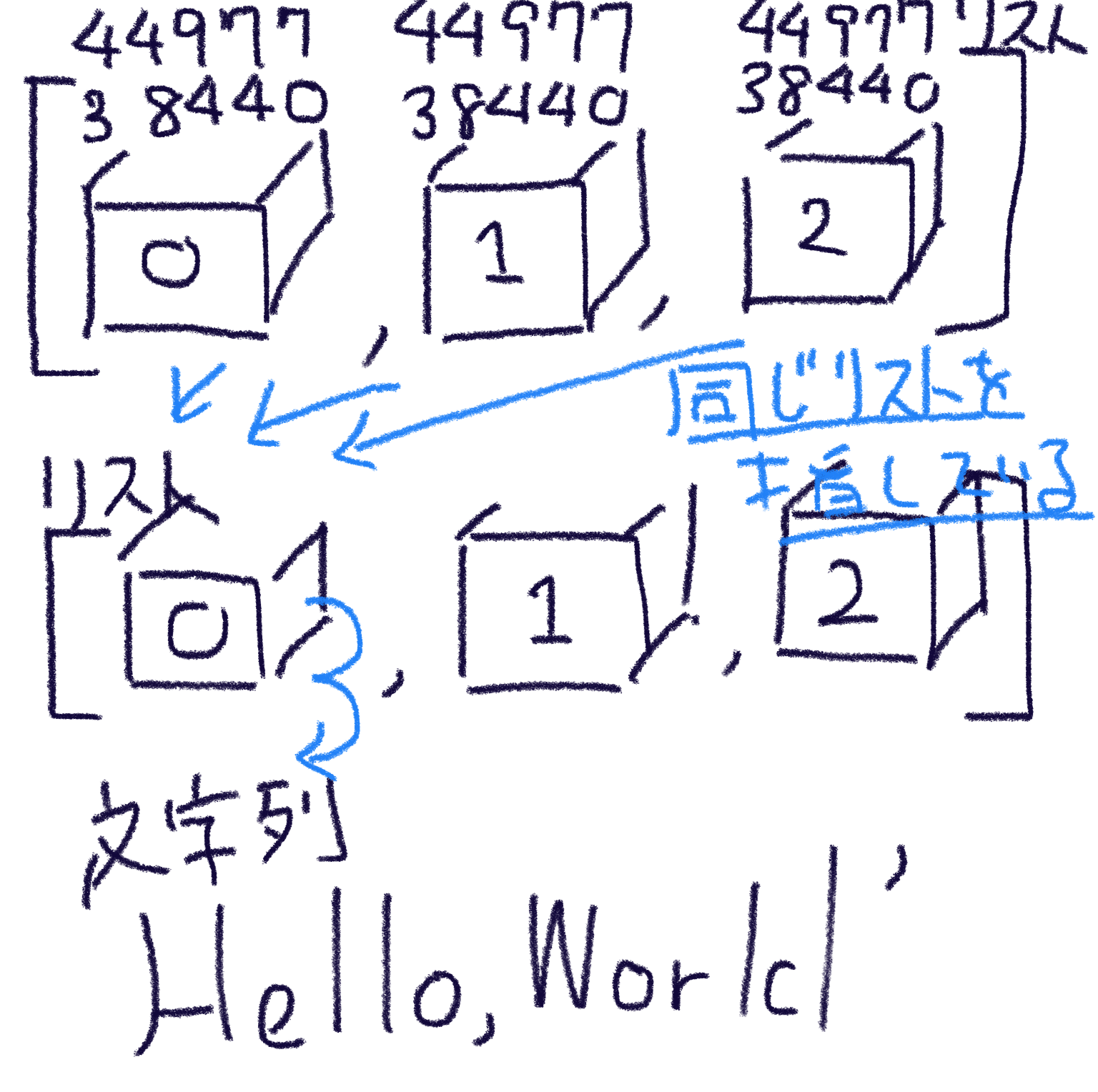
>>> [id(e) for e in lst]
[4497738440, <--- 全部同じ identity が表示された。
4497738440,
4497738440]
>>> lst
[['Hello', None, None],
['Hello', None, None],
['Hello', None, None]]
>>>
id 関数は identity を表示してくれる組み込み関数です。 identity とはオブジェクトが持っている背番号のようなものです。 ここのでポイントは、変数はオブジェクトを指し示しているだけだということです。
lst[0], lst[1], lst[2] は同じ1つのリストオブジェクトを指してしまっています。
そのため1つ lst[0][0] を書き換えれば
lst[1][0] も lst[2][0] も書き換わってしまったというわけです。
わかりにくい図ですが、こんな感じです。
正しくは以下のようにします。
# 正しい例
lst = [[None] * 3 for _ in range(3)]
lst[0][0] = 'Hello'
[id(e) for e in lst]
lst
>>> [id(e) for e in lst]
[4497697224, <--- 全部違う identity が表示された。
4497812680,
4497812744]
>>>
>>> lst
[['Hello', None, None],
[None, None, None],
[None, None, None]]
>>>
以上のことから、 リスト内包表記の場合は、その都度インスタンス化していることがわかりました。 それに対して、 掛け算の場合は、1度生成したオブジェクトをすべての要素に代入していることがわかりました。
もうちょっと込み入った例を用意しました。
対話モード >>> にコピペで実行できます。
ここでの 変更できない オブジェクトとは immutable のことではありません。 根本的に変更できないということです。 具体的には以下のクラスのオブジェクトが該当します。
# この辺だけ知っておけば OK
int
bool
str
type(None)
# この辺はなんとなくで
float
complex
bytes
type(Ellipsis)
type(NotImplemented)
type
types.BuiltinFunctionType
types.FunctionType # <-- これは変更できるけどシングルトンなので OK
例えば tuple は、すこし複雑です。 tuple は immutable ですが、変更できないオブジェクトではないからです。
もし tuple の中身が変更できないオブジェクトであれば、掛け算を使ってもいいですが。 tuple の中身が変更できるオブジェクトの場合は、掛け算を使ってはいけません。 これはなぜでしょうか?
# これはダメ
lst = [([], [], [])] * 20
なぜなら tuple の中身が変更できる場合、 次のような事故が起こってしまう可能性があります。
# 事故の例
lst = [([], [], [])] * 3
lst[0][2].append('Hello, world!')
print(lst)
>>> print(lst)
[([], [], ['Hello, world!']), ([], [], ['Hello, world!']), ([], [], ['Hello, world!'])]
>>>
正しくはリスト内包表記を使います。
# 正しくは...
lst = [([], [], []) for _ in range(3)]
lst[0][2].append('Hello, world!')
print(lst)
>>> print(lst)
[([], [], ['Hello, world!']), ([], [], []), ([], [], [])]
>>>
実際、標準ライブラリ copy の中にある関数 deepcopy でも、 tuple については特別な取り扱いがなされているように見えます。
根拠はどこにあるのでしょうか? 基本的に標準ライブラリ copy の deepcopy 関数の実装を元にご紹介させていただいております。 標準ライブラリ copy にある deepcopy 関数で _deepcopy_atomic を 使ってコピーされるオブジェクトのクラスを列挙しています。
_deepcopy_dispatch = d = {}
def _deepcopy_atomic(x, memo):
return x
d[type(None)] = _deepcopy_atomic
d[type(Ellipsis)] = _deepcopy_atomic
d[type(NotImplemented)] = _deepcopy_atomic
d[int] = _deepcopy_atomic
d[float] = _deepcopy_atomic
d[bool] = _deepcopy_atomic
d[complex] = _deepcopy_atomic
d[bytes] = _deepcopy_atomic
d[str] = _deepcopy_atomic
try:
d[types.CodeType] = _deepcopy_atomic
except AttributeError:
pass
d[type] = _deepcopy_atomic
d[types.BuiltinFunctionType] = _deepcopy_atomic
d[types.FunctionType] = _deepcopy_atomic
d[weakref.ref] = _deepcopy_atomic
...
del d
ここまで以下のような流れでご紹介させていただきました。
リストの初期化については「変更できない」オブジェクトを知るために、 deepcopy の実装を少しだけのぞいて見ました。 とは言え、重箱の隅をつついているので、 基本全部リスト内包表記で初期化してもいいんじゃないかなと思います。
標準ライブラリ copy のコードを見てきました。 次のページでは標準ライブラリ copy を掘り下げていきたいと思います。