
6.2. 例外か関数か
例外の方が速い
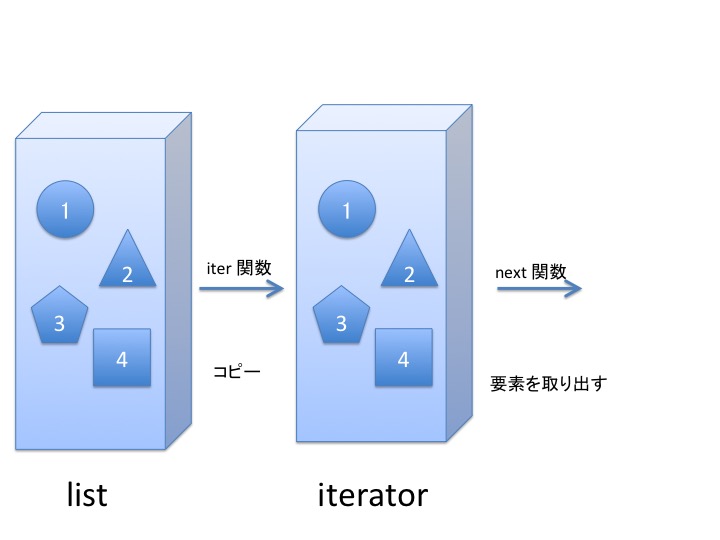
イテレータはリストのコピーみたいなものです。 そしてイテレータは for 文と、とても深く関わっています。
| 1 ~ 3 章 | ... | イテレータを触ってみる。 |
| 4 ~ 9 章 | ... | イテレータを実装する。 |
| 10 ~ 11 章 | ... | イテレータとコンテナを区別する。 |
| 12 ~ 13章 | ... | 2つの疑問について考える。 |
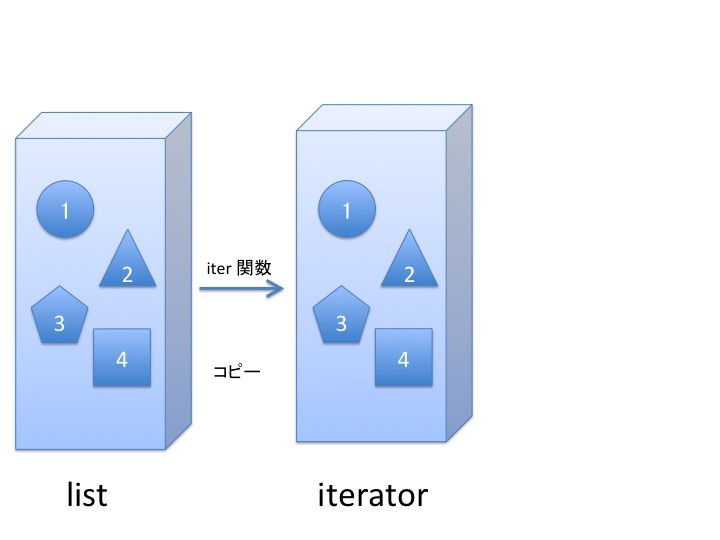
イテレータとは、list, tuple, set などの集合を表現するオブジェクトを iter 関数 を使って コピー したようなものです。
#
# 対話モード >>> に
# コピペで実行できます。
#
リスト = [1, 2, 3, 4]
イテレータ = iter(リスト)
イテレータ
list(イテレータ)
>>> イテレータ
<list_iterator object at 0x10d8458d0>
>>> list(イテレータ)
[1, 2, 3, 4] # <--- イテレータは、コピーみたいなもの
>>>
iter(object[, sentinel]) (opens new window)
イテレータ (iterator) オブジェクトを返します。
イテレータからは next 関数 を使って、 1つずつ要素を 取り出す ことができます。
リスト = [1, 2, 3, 4]
イテレータ = iter(リスト)
next(イテレータ)
next(イテレータ)
next(イテレータ)
next(イテレータ)
next(イテレータ)
next(イテレータ)
>>> next(イテレータ)
1
>>> next(イテレータ)
2
>>> next(イテレータ)
3
>>> next(イテレータ)
4
>>> next(イテレータ)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
StopIteration
>>>
next(iterator[, default]) (opens new window)
iterator の __next__() メソッドを呼び出すことにより、 次の要素を取得します。 イテレータが尽きている場合、 default が与えられていればそれが返され、 そうでなければ StopIteration が送出されます。
空っぽになった状態で next で呼ばれるとイテレータは StopIteration を投げ返してきます。
exception StopIteration (opens new window)
組込み関数 next() と iterator の __next__() メソッド によって、 そのイテレータが生成するアイテムがこれ以上ないことを伝えるために送出されます。
動作を図示するとこんな感じです。 ざっくり、てきとーに眺めてください。 イテレータは、list, tuple, set などの集合を表現するオブジェクトから iter 関数で生成された コピーみたいなもの だと考えてください。
イテレータから1つ1つ要素を取り出すには next 関数を使います。
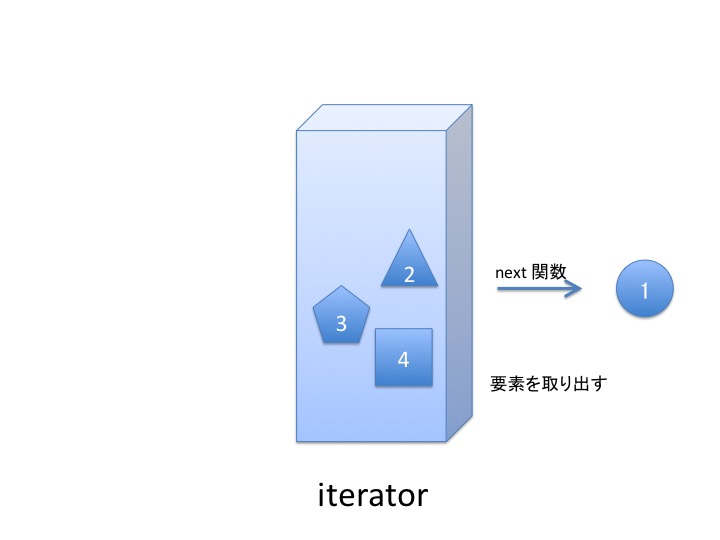
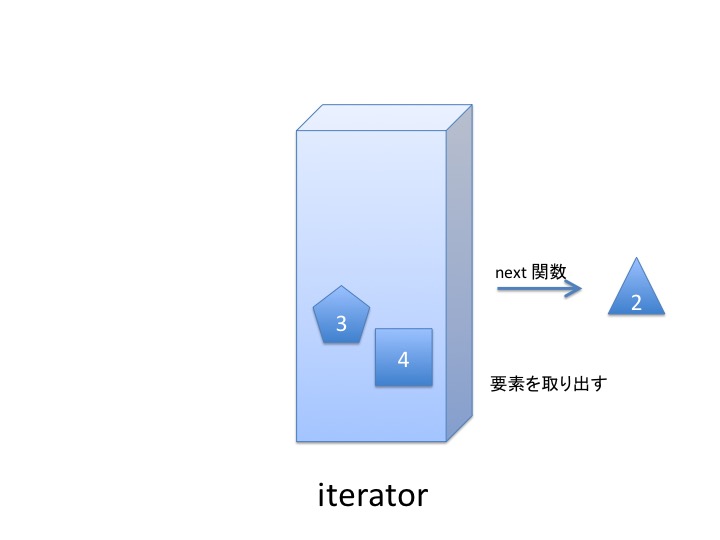
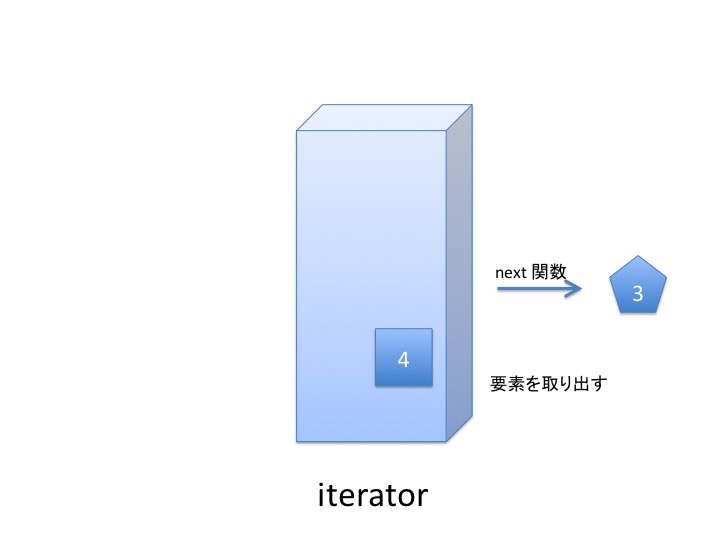
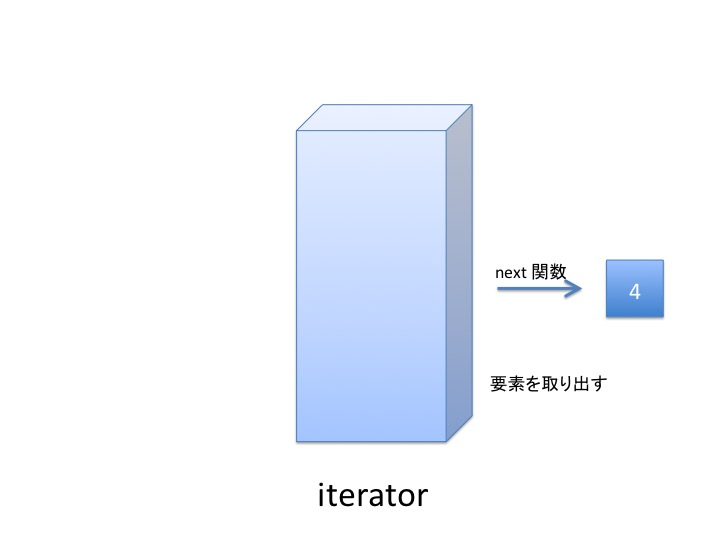
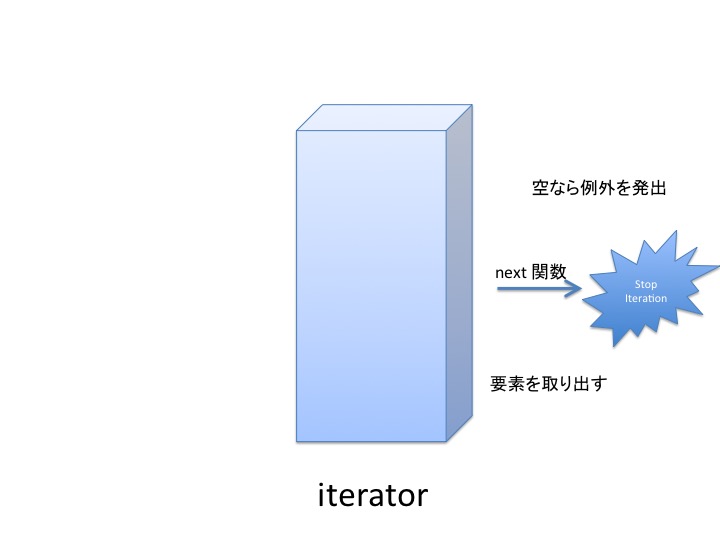
使い終わると イテレータは空っぽになりますが リストはそのままです。
全体像は、こんな感じになります。
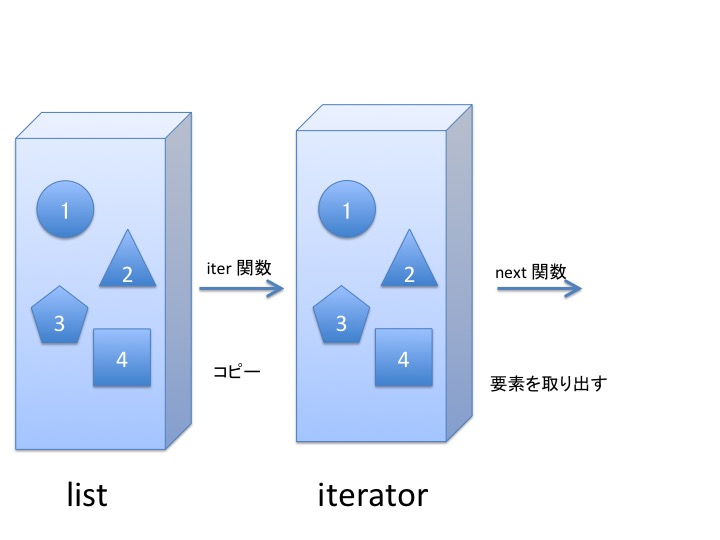
イテレータはコピーみたいなものです
なぜなら for 文があるからです。
1つずつ手打ちして next 関数で取り出すのも、
#
# 対話モード >>> に
# コピペで実行できます。
#
リスト = [1, 2, 3, 4]
イテレータ = iter(リスト)
要素 = next(イテレータ)
print(要素)
要素 = next(イテレータ)
print(要素)
要素 = next(イテレータ)
print(要素)
要素 = next(イテレータ)
print(要素)
要素 = next(イテレータ)
print(要素)
要素 = next(イテレータ)
print(要素)
while 文で取り出すのも面倒です。
#
# 対話モード >>> に
# コピペで実行できます。
#
リスト = [1, 2, 3, 4]
イテレータ = iter(リスト)
while True:
try:
要素 = next(イテレータ)
except StopIteration:
break
print(要素)
... print(要素)
...
1
2
3
4
>>>
iter でイテレータを生成して next で取り出して StopIteration で終了するまでの判定は、 for 文で自動的に繰り返す(iterate する)ことができます。
#
# 対話モード >>> に
# コピペで実行できます。
#
リスト = [1, 2, 3, 4]
for 要素 in リスト:
print(要素)
>>> for 要素 in リスト:
... print(要素)
...
1
2
3
4
>>>
要素を取り出す処理は、基本 for 文を使います。 iter 関数, next 関数を使って、 イテレータを直接操作することは稀かなと思います。
実は for 文はイテレータを回していました
答え: 簡潔なコードが書けるようになります。
イテレータを直接使うことがないなら、これを勉強して何が嬉しいのでしょうか? イテレータを理解して、自分で定義できるようになると、次のようなことができるようになります。
例えば for 文を次のように回していたものを
#
# 対話モード >>> に
# コピペで実行できます。
#
class Team:
def __init__(self):
self._member_list = []
team = Team()
team._member_list.extend(
['川島 永嗣', '香川 真司', '長谷部 誠'])
for member in team._member_list:
print(member)
>>> for member in team._member_list: # <- 長い
... print(member)
...
川島 永嗣
香川 真司
長谷部 誠
>>>
こんな風に in の中に自分が定義したクラスのオブジェクトが書けるようになります。
次のコードを対話モードにコピペして実行してみてください。
対話モードというのは、あのトンガリマークが3つ連なった >>> 記号が表示される画面ことです。
#
# 対話モード >>> に
# コピペで実行できます。
#
class Team:
def __init__(self):
self._member_list = []
def __iter__(self): # <- これを付け足すだけ
return iter(self._member_list)
team = Team()
team._member_list.extend(
['川島 永嗣', '香川 真司', '長谷部 誠'])
for member in team:
print(member)
>>> for member in team: # <- 短い
... print(member)
川島 永嗣
香川 真司
長谷部 誠
>>>
上記のように for 文の in に書き込めるできるインスタンスオブジェクトまたはクラスを イテラブル と言います。 Team はイテラブルです。 イテラブルは、この先かなり頻繁に登場する単語です。
set 関数を用いて差集合、和集合を取ったり、 max 関数を用いて集合の最大値を取ったりすることもできるようになったりもします。
こんな風に書いていたのを
#
# 対話モード >>> に
# コピペで実行できます。
#
class Team:
def __init__(self):
self._member_list = []
team_a = Team()
team_a._member_list.extend(
['川島 永嗣', '香川 真司', '長谷部 誠'])
team_b = Team()
team_b._member_list.extend(
['川島 永嗣', '香川 真司', '原口 元気'])
set(team_a._member_list) - set(team_b._member_list)
>>> set(team_a._member_list) - set(team_b._member_list)
{'長谷部 誠'}
>>>
こんな風に書き換えたりもできたりします。 次のコードを対話モードにコピペして実行してみてください。
#
# 対話モード >>> に
# コピペで実行できます。
#
class Team:
def __init__(self):
self._member_list = []
def __iter__(self): # <- これを付け足すだけ
return iter(self._member_list)
team_a = Team()
team_a._member_list.extend(
['川島 永嗣', '香川 真司', '長谷部 誠'])
team_b = Team()
team_b._member_list.extend(
['川島 永嗣', '香川 真司', '原口 元気'])
set(team_a) - set(team_b)
>>> set(team_a) - set(team_b) # <- 短くなりました。
{'長谷部 誠'}
>>>
他にもイテラブルを引数に取る関数が使えるようになります。 公式マニュアルの 組み込み関数のページ (opens new window) で ブラウザから ctrl + F をして検索 iterable をキーワードにして検索するといくつか引っかかってきます。 例えば all, any, dict, enumerate, min, sorted, sum, tuple, zip 関数で使えます。
少しだけコードを短く書けるからと言って、何が嬉しいのでしょうか? 上手くやると、ほんの少しですが、直感的にわかりやすいコードになることがあります。
こうやってコードを短くすることを「抽象化の度合いを上げる」と 表現されたりすることがあります。 うまく説明できないのですが、 コードの雰囲気が、ごくごく少しですが変わります。
# チームは、メンバーが所属している。
set(team._member_list)
# チームは、メンバーから成り立っている。
set(team)

こじつけ感満載で「また適当なこと言ってー」って感じですが、 他にもこのようなコードを短縮をする機能として「メソッド」があります。
メソッドは、定義するときは関数の第一引数 self を書かなければいけません。 しかし、呼び出す時は self を省略することができます。
#
# 対話モード >>> に
# コピペで実行できます。
#
class Team:
def __init__(self):
self._member_list = []
def __iter__(self):
return iter(self._member_list)
def extend(self, member_list):
self._member_list.extend(member_list)
team = Team()
# x 読みにくい(TypeError)
# team.extend(member, ['長谷部 誠', '三浦弦太', '冨安健洋'])
# o 読みやすい
team.extend(['長谷部 誠', '三浦弦太', '冨安健洋'])
team._member_list
Python では、他にも様々なコードを短くできる「抽象化度合いを上げる」機能があります。
書籍 Effective Python の「4 章 メタクラスと属性」に、
かなりまとまっています。
また、この記事でも、このあと __getitem__ メソッドを、ご紹介します。
ただし「抽象化度合いを上げる」と、「コードが追いかけづらくなる」ので、 余力があれば、勉強してもいいかな、くらいの温度感です。 「追いかけづらくなる」というのは、 どこから読めば良いのか分からなくなるということです。
コードが追いかけづらい
4. 全てが抽象化されすぎている
まずコードの可読性を最適化しよう - POST (opens new window)
「抽象化度合い」をあげるのは上手くやらないと、 書く側は気持ちいいのですが、読む側は辛かったりします。 「やっぱ、ワイは天才」って思いながら書いたコードが、 「なんや、このキチガイコード」って突き返される悲劇に、見舞われたことがあります。
簡潔なコードが書けるようになります
自分で定義したクラスを for 文で回して見たい... そう思ったことはありませんか? そんな疑問にここでは答えてきます。
for 文が実行されているとき
リスト = [1, 2, 3, 4]
for 要素 in リスト:
print(要素)
内部ではこんな感じで呼び出されています。
リスト = [1, 2, 3, 4]
イテレータ = iter(リスト)
while True:
try:
要素 = next(イテレータ)
except StopIteration:
break
print(要素)
実際には iter 関数も next 関数も、 それぞれ __iter__ メソッド, __next__ メソッドをそれぞれ呼び出しているだけです。
#
# 対話モード >>> に
# コピペで動きます。
#
リスト = [1, 2, 3, 4]
イテレータ = リスト.__iter__()
while True:
try:
要素 = イテレータ.__next__()
except StopIteration:
break
print(要素)
と、言うことは __iter__ メソッド, __next__ メソッドを定義できれば、 自分で定義したクラスのオブジェクトを for 文で使えるようになるのではないでしょうか?
Thas's right! その通りです。答え: 使い分けています。
ユーザが自分で iterator を定義したいときは __iter__, __next__ メソッドから定義します。 実際に使うときは iter, next 関数から呼び出します。
__iter__, __next__ メソッドと iter (opens new window), next (opens new window) 関数が 取る引数の違いに注目してください。 iter, next 関数は、__iter__, __next__ メソッドと異なり optional な引数を取ります。
iter, next 関数は、単純に __iter__, __next__ メソッドを実行するだけでなく optional な引数を取り、それに基づいて異なる処理をします。 optional な引数に基づく iterator に共通する処理は、組み込み関数が担ってくれるというわけです。
ちなみに Python では、このように __do__ メソッドを do 関数で呼び出すような書き方を定めてるものとして、 他にも len, bool があります。リンク先でもう少し詳しい解説をしています。
__iter__, __next__ メソッドを実装して、イテレータを自作していくことになります。
__iter__ と __next__ を定義する
ここからは、表記をすこし英語に切り替えていきます。 イテレータは iterator と書いていきます。
またリストは、タプルや辞書などの集合を表現するオブジェクトを総称する container と表現していきます。
container = [1, 2, 3, 4]
iterator = iter(container)
next(iterator)
container - Python 言語リファレンス (opens new window)
他のオブジェクトに対する参照をもつオブジェクトもあります; これらは コンテナ (container) と呼ばれます。 コンテナオブジェクトの例として、タプル、リスト、および辞書が挙げられます。オブジェクトへの参照自体がコンテナの値の一部です。 — ワイの注記 container について記述されている箇所の抜粋しました。 タプル、リスト、および辞書など集合を表現するオブジェクトを container だと言いたい様子。 ただ、この定義だと全てのオブジェクトが container に該当してしまうんじゃまいか..
コンテナ (データ型) - Wikipedia (opens new window)
コンテナとはオブジェクトの集まりを表現するデータ構造、抽象データ型またはクラスの総称である。
表記を切り替えて、
いままで触ってきた内容を元に、実装したいクラス、メソッドを図に落とすと次のようになります。
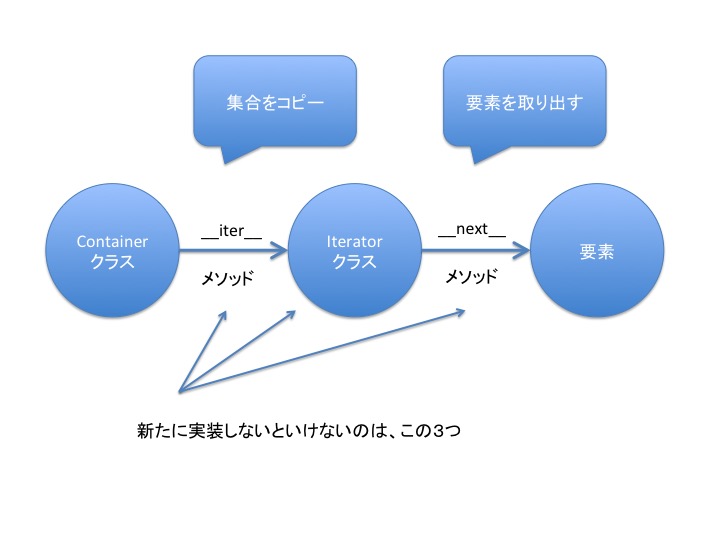
この図を見ると自分が作った container を for 文の in にいれたい場合は、 container に __iter__ メソッドを追加して、 iterator には __next__ メソッドを実装さえしてしまえば良さそうですね。
ここまでは iterator を触って大体の動作を把握しました。 ここから先は空集合、リスト、木の3つのデータ構造についてそれぞれ iterator を自作して理解を深めていきたいと思います。
| 6 章 | ... | iterator を自作する1 空集合 |
| 7 章 | ... | iterator を自作する2 リスト(コピー) |
| 8 章 | ... | iterator を自作する3 リスト |
| 9 章 | ... | iterator を自作する4 木 |
container と iterator
やっと自作するところまでたどり着きました。 空集合とか、気取って書いて見ましたが、 何も要素を持たない iterator と言うことです。
このクラスを
class Container:
pass
for 文の in に使えるようにします( iterable にします)。 最も小さい iterable を実装していきます。
>>> # 何も起こらない。とにかくエラーが発生しないことを目標に。
>>> for element in Container():
... print(element)
>>>
公式のマニュアルを読みながら、実装を進めて見たいと思います。 公式マニュアルと仲良くなることも、このページの目的です。
Python はコンテナでの反復処理の概念をサポートしています。 この概念は 2 つの別々のメソッドを使って実装されています; これらのメソッドを使ってユーザ定義のクラスで反復を行えるようにできます。
4.5. イテレータ型 - 標準ライブラリ (opens new window)
まず iterate させたい値を持つ container オブジェクトに対して iterator オブジェクトを返す __iter__ メソッドを定義する。
コンテナオブジェクト に反復処理をサポートさせるためには、以下のメソッドを定義しなければなりません。
container.__iter__() (opens new window)
イテレータオブジェクトを返します。
container オブジェクト に対しては何か明確な定義があるわけではありません。 list, tuple, set などの集合を表現するオブジェクトを総称して、ざっくり container だと言いたい様子です。
他のオブジェクトに対する参照をもつオブジェクトもあります; これらは コンテナ (container) と呼ばれます。 コンテナオブジェクトの例として、タプル、リスト、および辞書が挙げられます。 オブジェクトへの参照自体がコンテナの値の一部です。 ほとんどの場合、コンテナの値というと、 コンテナに入っているオブジェクトの値のことを指し、 それらオブジェクトのアイデンティティではありません;
3.1. オブジェクト、値、および型 - 言語リファレンス (opens new window)
コンテナ - Wikipedia (opens new window)
コンピュータプログラミングにおいて、 コンテナとはオブジェクトの集まりを表現するデータ構造、 抽象データ型またはクラスの総称である。 コレクションとも言う。コンテナには複数の種類があり、 それぞれ独自の方法でオブジェクトを組織的に格納する。
container が曖昧なのに対して iterator にも iterable にも、明確な定義があります。 それについてはこの記事の次「イテラブルってなに?」で考えていきます。 型アノテーションを使ってコーディングをするときに役立つ知識です。
次に iterator オブジェクトには、次の2つのメソッドを定義する。 イテレータオブジェクト自身を返す __iter__ メソッド と、 次の要素を返す __next__ メソッド。
イテレータオブジェクト自体は 以下の 2 つのメソッドをサポートする必要があります。
iterator.__iter__() (opens new window)
イテレータオブジェクト自体を返します。
iterator.__next__() (opens new window)
コンテナの次のアイテムを返します。もしそれ以上アイテムが無ければ StopIteration 例外を送出します。
イテレータオブジェクト自体を返す iterator.__iter__() と言うのがメソッドが新しく登場してきました。ちょっと、図を更新してみます。
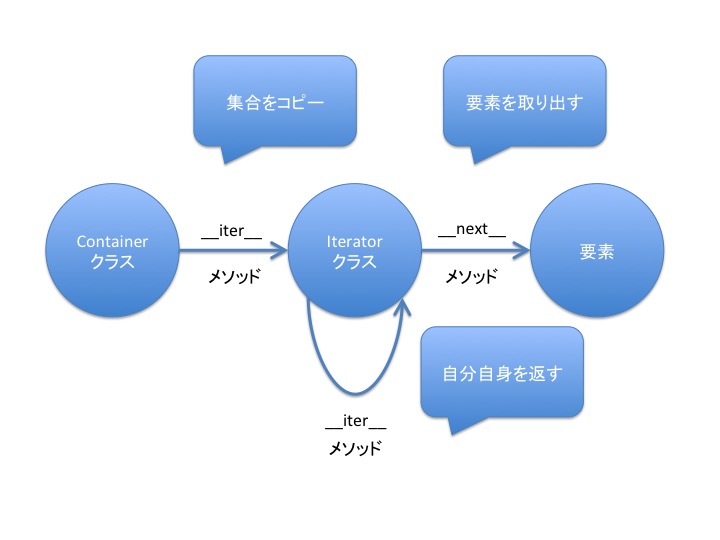
この iterator.__iter__() は何者かと言うと、 コンテナだけではなくイテレータそのものも for 文の in の中で使えるようにするためにあります。 イテレータであるかどうかを判別するために利用しています。
しかし iterator.__next__() があれば、イテレータだと判断できるのではないでしょうか? なぜ、わざわざ iterator.__iter__() を実装しなければならないのでしょうか?
それについても、この次の記事「イテラブルってなに?」の中で紹介させていただきます。
あらためて問題です。__next__ メソッドを実装して見て下さい。
class Container:
def __iter__(self):
return Iterator()
class Iterator:
def __iter__(self):
return self
def __next__(self):
# 問題: このメソッドを実装して下さい。
...
for element in Container():
print(element)
期待される動作は次のような具合です。 空っぽのコンテナなので、実行してもなにも表示されません。 とにかく for 文の in に代入できるオブジェクトを生成することです。
>>> for element in Container():
... print(element)
...
>>>
StopIteration
list を属性に持つクラスを iterable にして for 文で使えるようにしましょう。 ただし、理解のために iter 関数を使わずに自分でイテレータクラスを実装してみたいと思います。
# このままでは for 文で使えない, iterable でない
class Container:
def __init__(self, list_):
self._list = list_
for 文内で iterator が実行されると 文字列を繰り返す(iterate)するように実装して見ましょう。
>>> container = Container(
... ['Yaruo', 'Yaranaio', 'Yarumi'])
>>>
>>> for element in container:
... print(element)
...
Yarumi
Yaranaio
Yaruo
>>>
リストのコピーを使って実装して見ます。 これは誤った実装方針なので、ご自身で実装される必要は全くありません。 以下、こちらで実装したものをご提示したします。
実装するとこんな感じになります。 次のコードを対話モードにコピペして実行してみてください。
class Container:
def __init__(self, list_):
self._list = list_
def copy(self):
return self._list.copy()
# container.__iter__()
def __iter__(self):
# iter 関数を使わずに
# return iter(self.list)
return Iterator(self)
class Iterator:
def __init__(self, container):
self._list = container.copy()
# iterator.__iter__()
def __iter__(self):
return self
# iterator.__next__()
def __next__(self):
if self._list:
return self._list.pop()
# シーケンスが空であれば終了
else:
raise StopIteration
container = Container(['Yaruo', 'Yaranaio', 'Yarumi'])
for element in container:
print(element)
>>> container = Container(['Yaruo', 'Yaranaio', 'Yarumi'])
>>> for element in container:
... print(element)
...
Yarumi
Yaranaio
Yaruo
>>>
Container クラスは list クラスを継承せずに __init__ の中で属性 _list に インスタンスが代入されています。これを 合成 と言います。
また Container クラスの copy メソッドは、_list の copy メソッドを呼び出しているだけです。 これを 委譲 と言います。
なぜわざわざ Container に copy メソッドを書いたかというと
結合度
を下げるためです。
簡単に言えば self._container._list.copy() と書かないためです。
このようにドット . で長く書き込んでしまうと結合度が大きいコードになってしまうからです。
合成、委譲そして結合度については 継承よりも合成 で
ご紹介させていただきます。
リストのコピーは効率が悪そう...
メモリを消費するから。copy を実行してしまうと、その分だけメモリが増加してしまいます。
この前の記事である 「ジェネレータ」と「map, filter」では、実際にそのことを確認してきました。
コピーをしないで済ませるには、どうすれば良いでしょうか? インデックスだけ保存しておくようにしておけば、 そのような事態を避けることができます。
本当のことを言えば、 イテレータはコピーではありません。
>>> iter([1, 2, 3])
<list_iterator object at 0x103ec02b0>
>>>
list のイテレータである list_iterator クラスもリストのコピーでは、ありません。 そのため list を空にすると list_iterator も空になってしまいます。 次のコードを対話モードにコピペして実行してみてください。
lst = [1, 2, 3]
iterator = iter(lst)
# lst を空にすると
lst.pop()
lst.pop()
lst.pop()
lst.pop()
# iterator も空になる
list(iterator)
>>> lst = [1, 2, 3]
>>> iterator = iter(lst)
>>>
>>> # lst を空にすると
>>> lst.pop()
3
>>> lst.pop()
2
>>> lst.pop()
1
>>> lst.pop()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
IndexError: pop from empty list
>>>
>>> # iterator も空になる
>>> list(iterator)
[]
>>>
list を属性に持つクラスを iterable にして for 文で使えるようにしましょう。
__next__ メソッドを実装して見て下さい。
# このままでは for 文で使えない, iterable でない
class Container:
def __init__(self, list_):
self._list = list_
# 下に説明を書きました。
def __len__(self):
return len(self._list)
# 下に説明を書きました。
def __getitem__(self, index):
return self._list[index]
# container.__iter__()
def __iter__(self):
return Iterator(self)
class Iterator:
def __init__(self, container):
self._container = container
self._index = 0
# iterator.__iter__()
def __iter__(self):
return self
# iterator.__next__()
def __next__(self):
# 問題: このメソッドを実装してください。
...
container = Container(['Yaruo', 'Yaranaio', 'Yarumi'])
for element in container:
print(element)
__getitem__ メソッドは 添字表記 で参照されたときに呼び出されます。
上のコードでは結合度を下げるためにこのような書き方をしました。
__len__ メソッドは len 関数に引数として与えられたときに呼び出されます。
次のコードを対話モードにコピペして実行してみてください。
# 対話モードに
# コピペで実行できます。
class Sequence:
def __len__(self):
raise Exception('無限大のシーケンスです。')
def __getitem__(self, index):
return index
sequence = Sequence()
sequence[0]
sequence[1]
sequence[2]
sequence[100]
sequence[1000]
len(sequence)
>>> sequence = Sequence()
>>> sequence[0]
0
>>> sequence[1]
1
>>> sequence[2]
2
>>> sequence[100]
100
>>> sequence[1000]
1000
>>> len(sequence)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "<stdin>", line 3, in __len__
Exception: 無限大のシーケンスです。
>>>
リストのインデックスを使って、イテレータを実装します。
こちらに書きました。
この問題については是非自力で解いていただきたいです。 なぜなら Python のリストのイテレータを理解することにつながるからです。
また Python の公式ドキュメントのチュートリアルで
シーケンスを逆順する組み込み型 reversed (opens new window) と同じ動作をする
Reverse と言うイテレータを、実装、紹介されています。
9.8. イテレータ - Python チュートリアル (opens new window)
こんな車輪の再発明みたいなコード、どこで使うんや。と思われると思います。 実は、このようにしてインデックスを参照するやり方は CPython の list_iterator クラスと同じ実装になります。
ここで、ほんの少しだけ CPython の実装をのぞいて見たいと思います。 リストのインデックスを更新してるんだなってことだけを何となく眺めてもらえると嬉しいです。
もしわからなければ、キチガイが何かのたまいてるなという暖かい目で、読み流してください。 でも、もし「何だか Python を C に書き直してるだけやん」と感じて、CPython の入り口のきっかけになれば幸いです。
// class list_iterator(object):
typedef struct {
PyObject_HEAD
// self.index
Py_ssize_t it_index;
// self.list
PyListObject *it_seq;
} listiterobject;
// def __init__(self, list_):
static PyObject *
list_iter(PyObject *seq)
{
listiterobject *it;
if (!PyList_Check(seq)) {
PyErr_BadInternalCall();
return NULL;
}
it = PyObject_GC_New(listiterobject, &PyListIter_Type);
if (it == NULL)
return NULL;
// self.index = 0
it->it_index = 0;
Py_INCREF(seq);
// self.list = list_
it->it_seq = (PyListObject *)seq;
_PyObject_GC_TRACK(it);
return (PyObject *)it;
}
// def __next__(self):
static PyObject *
listiter_next(listiterobject *it)
{
PyListObject *seq;
PyObject *item;
assert(it != NULL);
seq = it->it_seq;
if (seq == NULL)
return NULL;
assert(PyList_Check(seq));
// if self.index < len(self.list):
if (it->it_index < PyList_GET_SIZE(seq)) {
// element = self.list[self.index]
item = PyList_GET_ITEM(seq, it->it_index);
// self.index += 1
++it->it_index;
Py_INCREF(item);
return item;
}
it->it_seq = NULL;
Py_DECREF(seq);
return NULL;
}
__iter__, __next__ メソッドでも、様々な機能を実装できます。 しかし、基本的には上記の内容に絞って実装した方が、可読性の高いコードになるかなと思います。
取り出した要素を2倍にする処理を例にして、考えてみたいと思います。
これが一番自然です。
for element in container:
element = 2 * element
class Container:
def __iter__(self):
return (2 * e for e in Iterator(self)) # <- ここを書き換えました。
class Iterator:
def __next__(self):
if self.index < len(self._container):
element = self._container[self._index]
self.index += 1
return 2 * element # <- ここを書き換えました。
else:
raise StopIteration
このことから、何が言えるでしょうか?
それはイテレータが、要素を1つずつ取り出すために設計されている言えるのではないかと感じました。 取り出した要素を 2 倍にするには、どんな書き方だってできます。 しかし、1度取り出して、それから処理をする。それが一番、わかりやすい書き方でした。
したがって、Python を習いたての人に「for 文とは何ですか?」と聞かれたら、 「要素を1つずつ取り出してくれます。」と説明すれば、基本的にはいいのかなと思ったりもします。
イテレータはコピーじゃない
もともと for 文で回せるリストを属性にくっつけただけのオブジェクトを iterable にしても「だからなんやねん?」って感じです。 list, tuple, dict, str などの最初から使える組み込み型は、 ある意味、オブジェクトが直線に並んでいると考えることもできます。
直線で並んでいるものを、1つずつ繰り返し取り出すこと iterate することは、頭の中で考える時はイメージしやすいです。 そこで今度は、すこし難易度を上げて直線で並んでいない型について、1つずつ繰り返し取り出すこと iterate することを考えて見ました。
こんなのもあるんだなくらいに流していただけると幸いです。
二分探索木, Binary Search Tree (opens new window) を iterable にして見ます。
二分探索木とは、「「左の子孫の値 ≤ 親の値 ≤ 右の子孫の値」という制約を持つ二分木である。 探索木のうちで最も基本的な木構造である。Wkipedia」だ、そうです。

二分探索木は、大小関係がわかるため、少ない計算量でソートして要素を取り出すことができます。 言い換えると、ある値の次に大きな値が、どれかを探しやすいということです。
>>> # 上図と同じ構造の木を作る。
>>> bst = BinarySearchTree()
>>> for value in (8, 3, 1, 6, 10, 4, 7, 14, 13):
>>> bst.insert(value)
>>>
>>> # 木から1つ1つ要素を取り出す。
>>> for value in bst:
print(value)
1
3
4
6
7
8
10
13
14
>>>
二分探索木の説明と実装は、こちらにまとめました。
イテレータは以下のようになります。 これだけ見せられてもなんだ?って感じだとは思うのですが。
class Iterator:
def __init__(self, node):
pseudo_node = BinarySearchNode(None)
pseudo_node.right = node
self._route = [pseudo_node]
def __next__(self):
if self._current_node().right:
self._seek_right_min()
else:
self._seek_right_parent()
return self._current_node().value
def _seek_right_min(self):
self._route.append(self._current_node().right)
while self._current_node().left:
self._route.append(self._current_node().left)
def _seek_right_parent(self):
try:
while self._route.pop() == self._current_node().right:
pass
except IndexError:
raise StopIteration
def _current_node(self):
return self._route[-1]
def __iter__(self):
return self
基本的な考え方は
ということを繰り返しています(図示予定)。
変な形をしたデータも for 文で使える。
for 文の中での表面的な動作は同じですが、イテレータとリストは全く違うものです。 では、どのようにして使い分ければいいでしょうか? 答え: もし、メモリを大量に消費するならイテレータを実装する。
イテレータは、オブジェクトのコピーを作りません。 イテレータは、メモリを少しだけしか消費しません。 イテレータの大体の構成は、 (1) コンテナの現在の要素と (先ほど自作した例で言ええばリストの self._index や木の self._route)、 (2) 現在要素から次の要素を取りに行く __next__ メソッドを持っているだけだからです。
import sys
# 重いです。
lst = list(range(10**7))
# list
# 大量のメモリを消費する
# -> for ループの度にコピーを作るのは非効率的
sys.getsizeof(lst)
# 90000112
# iterator
# メモリを消費しない
sys.getsizeof(iter(lst))
# 56
next 関数や for 文を使って、次の要素を取り出すことはできます。 しかし、イテレータを戻ったり(1つ前の要素を取り出したり)、 リストのようにいきなり 5 番目の要素を取得すると言ったことはできません。
リストは使いやすい、イテレータは省メモリ
コンテナは for 文に渡しても空にはなりません。 一方でイテレータは for 文で回すと空になります。 このことを知らないと、ちょっと長いこと悩むような事態に陥ります。
>>> # 空っぽになるイテレータの例
>>> file = open('sample.txt', 'r')
>>> for line in file: line
...
'Hello, world!\n'
'你好,世界!\n'
'こんにちは、世界!\n'
>>>
>>> # 空っぽになっている。
>>> for line in file: line
...
>>>
驚いたことに、ジェネレータの戻り値に ... 何も結果が得られません。... この振る舞いの原因は、イテレータが結果を一度だけしか生成しないことです。... 紛らわしいのは、すでに尽きてしまったイテレータに対して反復処理をしても、何のエラーも生じないことです。
項目17: 引数に対してイテレータを使うときには... - Effective Python (opens new window)
当たり前のことかもしれませんが、気をつけましょう。 弱い筆者はこれを解決するのに2時間(夕食休憩を含む)もかかってしまいました。
イテレータでファイルを扱う時は気をつけようねというお話 - Qiita (opens new window)
もう2回くらい躓いているんだけど, python で iterator をクラス変数なんかの関数をまたぐものにいれると盛大にバグる. 1回目は list と同様に舐められるけど2回目以降はなくなるという現象.
Twitter (opens new window)
コンテナには明確な定義はありませんが __iter__ メソッドを持っていて __next__ メソッドは持っていない クラスやそのオブジェクトをコンテナと呼びことにします。
普段よく使う list, dict, str などの組み込み型は、コンテナです。 それぞれ list_iterator, dict_keyiterator, str_iterator というイテレータを持っています。 イテレータとコンテナのクラスが、別々に別れています。
最初からユーザが定義せずとも使用できる list, dic, str などの型を 組み込み型 (opens new window) と呼びます。
>>> iter([1, 2, 3])
<list_iterator object at 0x1053d52b0>
>>>
>>> iter({'a':1, 'b':2, 'c':3})
<dict_keyiterator object at 0x1053c3a98>
>>>
>>> iter('Yaruo')
<str_iterator object at 0x1053d5208>
>>>
generator, filter, map, TextIOWrapper 型は、イテレータです。 ちなみに TextIOWrapper は、ファイルを読み込む時に使う open 関数から返されるオブジェクトです。
>>> open('sample.txt', 'r')
<_io.TextIOWrapper name='sample.txt' mode='r' encoding='UTF-8'>
>>>
これらのオブジェクトは、1度 for 文で回すと空っぽになります。 このことを知らないと、イテレータが空になっていることに気づけずに、長いこと悩むような事態に陥ります。 generator, map, filter, TextIOWrapper は直接触ることが多いため、空っぽのイテレータに引っかかりやすいイテレータかなと思います。
>>> lst = [0, 1, 2, 3]
>>> iterator = map(lambda x: 2*x, lst)
>>> for i in iterator: i
...
0
2
4
6
>>>
>>> # 空っぽになっている。
>>> for i in iterator: i
...
>>>
>>> file = open('sample.txt', 'r')
>>> for line in file: line
...
'Hello, world!\n'
'你好,世界!\n'
'こんにちは、世界!\n'
>>>
>>> # 空っぽになっている。
>>> for line in file: line
...
>>>
この節は Effective Python (opens new window) の 「項目17: 引数に対してイテレータを使うときには確実さを尊ぶ」 の劣化版です。その方法について、概略を3つ記します。
メリットは実装が簡単です。 デメリットは、for loop のたびに再代入するのが面倒です。
>>> lst = [0, 1, 2, 3]
>>> iterator = map(lambda x: 2*x, lst)
>>> for i in iterator: i
...
0
2
4
6
>>>
>>> # もう一回、再代入する。
>>> iterator = map(lambda x: 2*x, lst)
>>> for i in iterator: i
...
0
2
4
6
>>>
>>> # file.seek メソッドを使います。
>>> file = open('sample.txt', 'r')
>>> for line in file: line
...
'Hello, world!\n'
'你好,世界!\n'
'こんにちは、世界!\n'
>>> for line in file: line
...
>>> # 空っぽになる。
>>>
>>> # seek メソッドを使う。
>>> file.seek(0)
0
>>> for line in file: line
...
'Hello, world!\n'
'你好,世界!\n'
'こんにちは、世界!\n'
>>>
メリットは実装が簡単です。 デメリットはメモリを消費します。 もはやイテレータでは無くなります。 もしメモリの使用量が気にならないなら、これがいいと思います。
>>> lst = [0, 1, 2, 3]
>>> lst = list(map(lambda x: 2*x, lst))
>>> for y in lst: y
...
0
2
4
6
>>> for y in lst: y
...
0
2
4
6
>>>
>>> # リストに保存する。
>>> file = open('sample.txt', 'r')
>>> lst = list(file)
>>> lst
['Hello, worlf!\n', '你好,世界!\n', 'こんにちは、世界!\n']
>>>
>>> # 空っぽにならない。
>>> for line in lst: line
...
'Hello, worlf!\n'
'你好,世界!\n'
'こんにちは、世界!\n'
>>> for line in lst: line
...
'Hello, worlf!\n'
'你好,世界!\n'
'こんにちは、世界!\n'
>>>
メリットは、再代入しなくていい。デメリットは実装が面倒です。 いままで見てきた通り、iterator クラスと container クラスを分割して再設計します。 そうすれば for 文から抜けた後も、イテレータが空っぽになったりするようなこともありません。
# コピペで実行できます。
class Map:
def __init__(self, function, container):
self._function = function
self._container = container
def __iter__(self):
return map(self._function, self._container)
# 空っぽにならない
container = Map(lambda x: x**2, range(3))
for i in container: i
for i in container: i
イテレータの利点は、専用のイテレータを実装しないため、実装が簡単です。 欠点は、気づきにくいバグを引き起こしやすいです。これは for 文を回すと空っぽになるためです。
コンテナの欠点は、専用のイテレータクラスを実装しなければならず、手間がかかります。 利点は、イテレータのような気づきにくいバグを引き起こしにくいです。これは for 文を回しても空っぽにならないためです。
| 項目 | 実装 | バグに |
| コンテナ | めんどう | なりにくい |
| イテレータ | かんたん | なりやすい |
ここからは次の2つの疑問について考えてみます。
| 12 章 | ... | なんで StopIteration で判定するの? |
| 13 章 | ... | なんで map や filter は、 リストではなくてイテレータを返すの? |
速い。
速度については、以下の記事でご紹介させていただきました。 なぜ StopIteration を使うかについては PEP に記述がありましたので、 あわせてご紹介させていただきました。
例外は、コードが読みづらい。
どのコードが、どの例外をいつ発するのか、この try 文は何を期待しているのかを考えるのが辛い。 でも、それを for 文で包むことで、このデメリットを解消している。
答え: メモリの節約になるから
map は Python 2 のころは、リストを返す関数でした。
>>> # Python 2
>>> map(lambda x: 2*x, [0, 1, 2, 3])
[0, 2, 4, 6]
>>>
map は Python 3 では、イテレータを返すクラスに変更されました。map は、遅延評価するイテレータです。
>>> # Python 3
>>> map(lambda x: 2*x, [0, 1, 2, 3])
<map object at 0x1083f4470>
>>> list(map(lambda x: 2*x, [0, 1, 2, 3]))
[0, 2, 4, 6]
>>>
Python は ABC という教育用言語に影響を受けて可読性を重視して設計されました。
Python の開発のスタート時から、もっとも大きい影響を与えた言語は、 1980 年代の初め頃に Lambert Meetens 氏と Leo Geurts 氏などがオランダ国立情報数学研究所で言語設計を行ったABCである。 ABC は BASIC の代替の教育用言語を目指していた言語である。
初期の言語設計と開発 - The History of Python.jp (opens new window)
それにも関わらず、なぜ list(map(fun, iterable)) なんていう読みにくい、 初学者にとって理解しにくい変更をわざわざしたのでしょうか? 特に Python を習いたての頃は、map や filter からイテレータを返されると、 わかりにくくて戸惑ってしまいます。そもそもイテレータが何であるかさえ知らないですしね。
実際 map, filter について記事を書こうと思った時に、どうやってイテレータに触れないで説明するかですごく苦慮しました。
map, filter ってなに?
このような変更を施した理由は、リストのコピーを作るというのは、いままで見てきた通り、メモリを消費するからだと思っています。 Python のメーリングリストを漁ったら資料が出てくるかもしれない。
繰り返しになりますが イテレータは、next 関数が呼び出されたタイミングで計算します。 1度に計算をすべて行わないのでメモリを節約できます。
>>> # map クラス
>>> iterator = map(lambda x: 2*x, [1, 2, 3])
>>> # 要素を取り出して 2 * 1 を行う
>>> next(iterator)
2
>>> # 要素を取り出して 2 * 2 を行う
>>> next(iterator)
4
>>> # 要素を取り出して 2 * 3 を行う
>>> next(iterator)
6
>>> # 要素を取り出せないので raise StopIteration
>>> next(iterator)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
StopIteration
>>>
map は、公式のドキュメントでは「2. 組み込み関数 」の項目の中で説明されていますが map はクラスです。
これは Python 2 の頃は、map が関数だったことの名残だと思われます。
2. 組み込み関数 map
map だけではなく Python 2 から 3 になるにかけて、filter や zip もリストを返す関数から遅延評価するイテレータになりました。
リストからビューおよびイテレータへ
Python 2 では range はリストを返す関数で xrange は、 遅延評価する iterable をインスタンス化するクラスでした。 Python 3 では Python 2 のリストを返す range は廃止されて、 代わりに Python 2 の遅延評価する iterable をインスタンス化するクラスの xrange が range になりました (range クラスがインスタンス化したオブジェクトは iteable ではありますが、イテレータそのものはではありません)。
Python 2 の頃は range ではなく xrange を使いましょうと、 よく言われていました。これは例えば 10**100 回 for 文を回すために range(10**100) と書いてしまうと、 for 文を回しただけで多くのメモリを一瞬で消費してしまうためです。
多くの人がすでに知っているとは思いますが、xrange を使うのがベターです
for i in xrange(6): print 1**2xrange は range と違って一気にメモリを確保しないので、 メモリが節約できます。動画中 (opens new window) では、 xrange という名前は醜い!と言って笑いを取っていましたw ちなみに Python 3 では range が xrange と同様の動きをするようになりましたので、range を使用してOKです。
Pythonらしいコードの書き方 - Kesinの知見置き場 (opens new window)
map, filter そして zip からイテレータを返されたり、 range が iterable なオブジェクトになってしまうと、 最初は、わかりにくくて戸惑ってしまいます。 しかし、それでもリストを返す関数が廃止されてしまうくらい、 繰り返す iterate するときにはリストよりもイテレータの方が優れた実装ということではないでしょうか。
| 項目 | 実装 | メモリの使用量 |
| リスト | わかりやすい | 多い |
| イテレータ | むずかしい | 少ない |
それでは最後に for 文で使える、iterable とは何かについて触れてこの連載の締めくくりとさせていただきたいと思います。