
副作用ってなに?
属性の値が変わること。
関数型プログラミングは、簡単に言えば、変数または属性に再代入しないプログラミングです。
再代入を許さないプログラミングなんてできるのかよ?
と言う感じですが、やり方そのものは簡単です。 CRUD のうちの U, Update の処理が発生するたびに、新しくオブジェクトを作り直すだけです。
すると何が起こるのでしょうか?Update の処理を書かなくて良くなります。 Update の処理を書かなくて楽になります。 もちろん、辛くなるときもあります。 使い分けが必要かなと思います。
ここでは関数型言語に分類される Lisp という言語から輸入された map と filter を通して 関数型プログラミングについて、考えていきます。
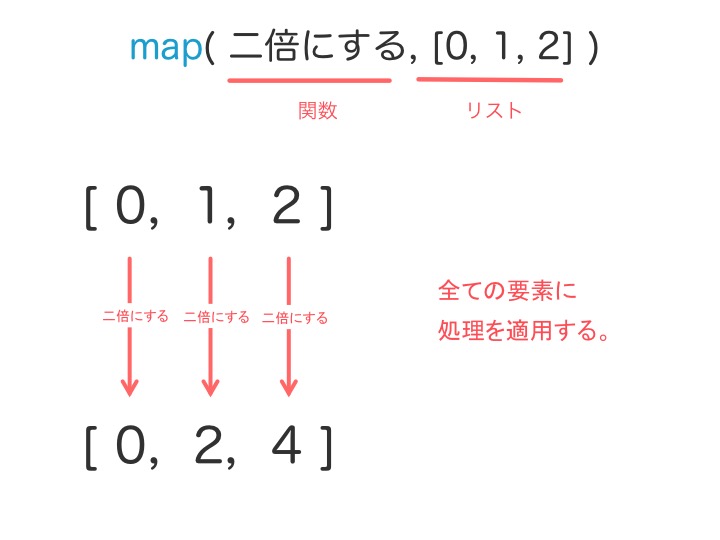
イテラブルの全ての要素に
関数を適用
します。
例えばリストの要素に2倍にする関数 二倍にする を適用したいときは、
for 文を使って次のように書きます。
#
# 対話モード >>> に
# コピペで実行できます。
#
リスト = [0, 1, 2]
def 二倍にする(x):
return 2 * x
新しいリスト = []
for 要素 in リスト:
新しいリスト.append(二倍にする(要素))
print(新しいリスト)
>>> print(新しいリスト)
[0, 2, 4]
>>>
こうやってリストの全ての要素に何か処理を実行したいということはよくあります。
そんなよくあることなので map が用意されいます。
map を使うともっとあっさりと書けます。
for 文を短くかける
と言うのが map の1つのメリットです。
#
# 対話モード >>> に
# コピペで実行できます。
#
リスト = [0, 1, 2]
def 二倍にする(x):
return 2 * x
新しいリスト = list(map(二倍にする, リスト))
print(新しいリスト)
>>> print(新しいリスト)
[0, 2, 4]
>>>
なんで list と書いているのでしょうか?
新しいリスト = list(map(二倍にする, リスト))
ここでのポイントは map(二倍にする, リスト) は、リストを返していないということです。
そのため print してもよくわかならいものが表示されます。
表示して見ましょう。
#
# 対話モード >>> に
# コピペで実行できます。
#
リスト = [0, 1, 2]
def 二倍にする(x):
return 2 * x
mapオブジェクト = map(二倍にする, リスト)
新しいリスト = list(mapオブジェクト)
print(mapオブジェクト)
print(新しいリスト)
>>> print(mapオブジェクト)
<map object at 0x10ac67400> <--- こんなの見せられてもわからない...
>>>
>>> print(新しいリスト)
[0, 2, 4]
>>>
map は関数ではなくクラスです。
mapオブジェクト は、正確にはリストではありません。
しかし
mapオブジェクト は、リストみたいなもの
だと思っておいてください。
その理解で困ることはないはずです。
学習速度の速い方なら、もしかしたら 3 日後くらいには困るかもしれませんが、
自分はその理解で 10 年過ごしました笑
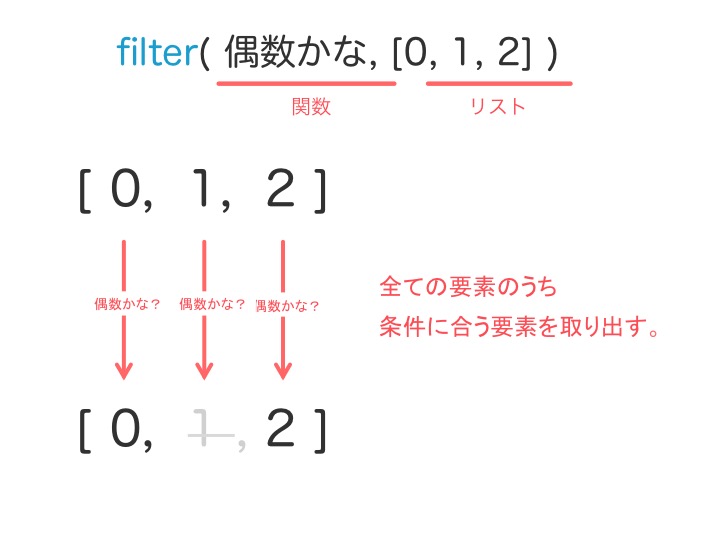
リストの各要素のうち
条件に満たないものを削除
します。
例えばリストから偶数の要素だけを取り出したいとします。
関数 偶数かな と for 文を使って次のように書きます。
#
# 対話モード >>> に
# コピペで実行できます。
#
リスト = [0, 1, 2]
def 偶数かな(x):
return x % 2 == 0
新しいリスト = []
for 要素 in リスト:
if 偶数かな(要素):
新しいリスト.append(要素)
print(新しいリスト)
>>> print(新しいリスト)
[0, 2]
>>>
これを filter を使うともっと短く書けます。
#
# 対話モード >>> に
# コピペで実行できます。
#
リスト = [0, 1, 2]
def 偶数かな(x):
return x % 2 == 0
新しいリスト = list(filter(偶数かな, リスト))
print(新しいリスト)
>>> print(新しいリスト)
[0, 2]
>>>
このようにして map, filter を使うと for 文を使わずに短く書けるようになる時があります。
上で見たサンプルコードの関数は 二倍にする, 偶数かな は、いずれもとても簡単なものです。
1行で定義から関数の実引数の代入までできたら便利そうな気がします。
lambda 式
でそれを実現できます。

lambda 式を使い上の例を書き換えて見ます。 関数を def で定義することなく簡潔に表現できています。
#
# Step 1.
# for 文
# def 文
#
リスト = [0, 1, 2]
def 二倍にする(x):
return 2 * x
新しいリスト = []
for 要素 in リスト:
新しいリスト.append(二倍にする(要素))
print(新しいリスト)
#
# Step 2.
# for 文 -> map クラス
# def 文
#
リスト = [0, 1, 2]
def 二倍にする(x):
return 2 * x
新しいリスト = list(map(二倍にする, リスト))
print(新しいリスト)
#
# Step 3.
# for 文 -> map クラス
# def 文 -> lambda 式
#
リスト = [0, 1, 2]
新しいリスト = list(map(lambda x: 2 * x, リスト))
print(新しいリスト)
>>> print(新しいリスト)
[0, 2, 4]
>>>
def 文と for 文の代わりに map クラスと lambda 式を使うことでとても短く書けるようになりました。 lambda 式は def 文と同じで関数を定義しているだけです。 細かいことろは違うのですが、それは次節で見ていきたいと思います。
def 二倍にする(x): return 2 * x
二倍にする(2)
二倍にする = lambda x: 2 * x
二倍にする(2)
>>> # def でも lambda でも
>>> # 実行結果は同じになります。
>>> 二倍にする(2)
4
>>>
以下のコードを def 文から lambda 式で書き換えてください。
リスト = [0, 1, 2]
# def 偶数かな(x):
# return x % 2 == 0
#
# 新しいリスト = list(filter(偶数かな, リスト))
新しいリスト = list('ここに lamnda 式を書いてください', リスト)
print(新しいリスト)
次の2つは全く同じ動作をします。 では lambda 式と def 文の違いはなんでしょうか?
# lambda 式
double = lambda x: 2 * x
double(2)
# 4
# def 文
def double(x):
return x
double(2)
# 4
def と lambda の違いは、次の3つになります。
| - | def | lambda |
|---|---|---|
| 1 | 複数行書ける | 一行しか書けない |
| 2 | 文 | 式 |
| 3 | 名前がある | 名前がない |
lambda 式は「式」なので、変数に代入できます。 しかし def を使う関数定義文は「文」なので、直接、変数に代入はできません。
def f(x): return x
# これは動く
g = def f(x): return x
# これはエラーになる
>>> def f(x): return x
>>>
>>> g = def f(x): return x
File "<stdin>", line 1
g = def f(x): return x
^
SyntaxError: invalid syntax
>>>
str 型で関数名を定義できるのは、どちらですか?
実は Python はセミコロン ; を使うと
単純文 (opens new window)
をつないで一行で書くことができるという裏技があります。
滅多に使ったことがないので、覚える必要はありません。
def f(x): y = x + 1; z = y + 2; return z;
f(0)
>>> def f(x): y = x + 1; z = y + 2; return z;
...
>>> f(0)
3
>>>
lambda 式の場合は ; を使ったりしても、
どう足掻いても複数行で書くことはできません。
f = lambda x: y = x + 1; z = y + 2; return z;
f(0)
>>> f = lambda x: y = x + 1; z = y + 2; return z;
File "<stdin>", line 1
SyntaxError: cannot assign to lambda
>>>
>>> f(0)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
NameError: name 'f' is not defined
>>>
どう足掻いても絶望 (opens new window)
ホラーゲーム SIREN のキャッチコピー
ま、絶望はしませんが。
リアルタイムで CM で見たときはガチでビビりました笑
ちなみに if 文, for 文, def を使う関数定義文は、
複数行使うので 複合文 (opens new window) と呼ばれ、
単純文とは区別されています。
複合文は、セミコロン ; でつなぐことはできません。
ちなみに lmabda 式は、たまに 無名関数 と呼ばれているのを目にします。 なぜ、無名関数と呼ばれるのでしょうか? ぱっと見 double という変数に代入しているので、 無名ではなさそうに見えます。
関数の名前は、特殊属性 __name__ で調べることができます。
どうでしょうか?
lambda で定義した関数は、すべて名前が <lambda> になってしまっていることが確認できます。
# 無名関数
double = lambda x: 2 * x
triple = lambda x: 3 * x
def quad(x):
return 4 * x
double.__name__
triple.__name__
quad.__name__
>>> double.__name__
'<lambda>' # <-- lambda になる
>>> triple.__name__
'<lambda>' # <-- lambda になる
>>> quad.__name__
'quad'
>>>
関数を引数に取ることができる関数を難しい言葉で 高階関数 と呼ばれているのを目にします。 map, filter は、高階関数です。 高階関数の引数に lambda 式を渡すと、
その関数の名前が何かわからなくなります。 これは一見ささいなようですが、デバックをするときに この子は誰?みたいなことになって苦しくなったりすることがあるそうです。
割り算 = lambda x, y: x / y
def 高階関数(四則演算, a, b):
return 四則演算(a, b)
高階関数(割り算, 1, 0)
>>> 高階関数(割り算, 1, 0)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "<stdin>", line 2, in 高階関数
File "<stdin>", line 1, in <lambda>
ZeroDivisionError: division by zero
>>>
スタックトレースを見てみましょう。
おやおやおや 割り算 となって欲しいところが
<lambda> になってしまっていますね。
>>> 高階関数(割り算, 1, 0)
in <module>
in 高階関数
in <lambda>
>>>
無名関数, lambda 式という言葉は JavaScript など他のプログラミング言語でもでてくる用語なので、 覚えておいても良い単語かなと思ったりします。
PEP 8 という コーディング規約 があります。 コーディング規約とは、みんなでこうやって書こうねと決めた「書き方」決まりごとです。 例えば、メソッドを定義するときに、いつも self と書いてるのも、この PEP 8 で定められています。
その PEP 8 では lambda は、式ですが、変数に代入しないように指示されています。 lambda を使用するのは、原則、関数を引数にとる関数(高階関数)に代入するときだけです。 また変数などに代入せず、そのまま引数として与えてください。
# OK
list(map(lambda x: x**2, range(10)))
# NG
f = lambda x: x**2
list(map(f, range(10)))
なぜかというと lambda 式を map, filter などの高階関数以外で使うと、 読みづらくなるからだそうです。 最初は、大袈裟やなーと思っていたのですが、 JavaScript を触るようになって、多用される無名関数に大変辛い思いをしています笑
おそらく lambda が一行しか使えないように制限されているのも、 そう言ったところにあるのかなと思ったりします。 ちょっと長いですが、以下 PEP 8 の文章を抜粋、引用します。
プログラミングにあたっての推奨事項 - PEP8 (opens new window)
Programming Recommendations - PEP8lambda 式を識別子に直接束縛する代入文ではなく、常に def 文を使ってっください。
Always use a def statement instead of an assignment statement that binds a lambda expression directly to an identifier.Yes:
def f(x): return 2*xNo: f = lambda x: 2*x
最初の形式は、結果としてえられる関数オブジェクトの名前が、 一般的な <lambda> ではなく 'f' という名前がつけられていることを意味しています。 関数オブジェクトに文字列の名前が与えられていることは、一般に例外が発生した時にそれをトレースバックさせたり、関数名を文字列で出力させる際に役立ちます。 代入文を使うことは(代入文で lambda 式を変数に束縛してから map, filiter などの高階関数に引数として与えることは)、 def 文にはなく lambda 式にある、たった1つの利点(すなわち、lambda 式は、より大きな式の中に埋め込められるということ)を無意味なものにしてしまいます。
The first form means that the name of the resulting function object is specifically 'f' instead of the generic '<lambda>'. This is more useful for tracebacks and string representations in general. The use of the assignment statement eliminates the sole benefit a lambda expression can offer over an explicit def statement (i.e. that it can be embedded inside a larger expression)
map, filter 以外に高階関数はあるのでしょうか? 実は、組み込み関数 max, min, sorted は、関数を引数に取ることができる高階関数だったりします。 import せずに使える関数を 組み込み関数 (opens new window) と言います。
max([0, 1, -2, 4, 10, -11, 2, 3], key=lambda x: x**2)
# -11 <- (-11)**2 が最も大きいので -11 が返されています。
また、高階関数に渡される関数を「コールバック関数」と、たまに呼ばれていたりします。
上の例で言えば lambda x: x**2 はコールバック関数です。
いろんな関数がでて来たので、最後に列挙しておきます。 名前を覚える必要は全くないのですが、 たまに Qiita とかで見かけて知らないと混乱するので、 心の片隅にあってもいいかなと。
map, filter オブジェクトは、 1度 for 文で回すと空になります 。 このことに引っかかって、 時間を費やしてしまった方を Twitter や Qiita でたまに見かけます。
map/zip/filter オブジェクトに対して、list を2回やると空っぽになります。 最初何が起こったのかわからずバグじゃないかとか、破壊的メソッドか!? などと思ったりしたわけですが、仕様らしいです。
python の map オブジェクトを list にした後は何も残らない - Qiita (opens new window)
簡単に確認してみます。
# 対話モード >>> にコピペで実行できます。
m = map(lambda x: x**2, range(3))
for e in m: e
for e in m: e
>>> for e in m: e
...
0
1
4
>>> for e in m: e
... # <- 何も起こらない。
>>>
なぜ、このようなことが起こるのでしょうか? それは map, filter がリストではなくイテレータだからです。 この原因の詳細は、この次で見ていきたいと思います。
とりあえず対応策だけ知りたい方は、こちらからどうぞ。 3つの対応策を示しています。
# 1) もう一回呼ぶ
iterator = map(lambda x: x**2, range(3))
# 2) リストにする
list_ = list(map(lambda x: x**2, range(3)))
# 3) コンテナクラスを作る
class Container:
def __init__(self, container):
self._container = container
def __iter__(self):
return map(lambda x: x**2, self._container)
container = Container(range(3))
上のコードで作った Container クラスのオブジェクトは、 何回 for 文で回しても空にはなりません。 3つ目の「コンテナクラスを作る」の仕組みについても、 「イテレータってなに?」 の中で見ていきたいと思います。
>>> for element in container:
... element
...
0
1
4
>>> for element in container:
... element
...
0
1
4
>>>
嘘をついていました。
# X (困ることはないけど...)
リスト = map(関数, リスト)
# O (正確には)
mapオブジェクト = map(関数, イテラブル)
list, tuple, dict, set など for 文で回せるオブジェクトなら、 なんでも引数に取れます。 for 文で回せるオブジェクトのことを イテラブル と言います。 str もイテラブルです。なので極端な話 str も引数に取れます。
s = 'abcdefg'
for e in map(lambda c: c + '!', s):
print(e)
# a!
# b!
# c!
# d!
# e!
# f!
# g!
map, filter は高階 関数 と書きましたが、 map, filter は、リストを返す関数ではありません。 map, filter は、クラスです。 組み込み型はクラス名が大文字でないので誤解しやすい。 例えば map クラスを使うと map オブジェクトが返されます。
map(lambda x: 2 * x, range(3))
# <map object at 0x10ebdb0f0>
isinstance(map, type)
# True
map, filter のリストの違いについて考えていきます。 リストは、for 文が実行される前から、全ての要素を存在しています。 それに対して map, filter は、for 文が回るたびに、 処理を起動をして要素を生成し、要素を渡したら処理を中断しています。
このようにして、必要になるまで処理を実行しないことを遅延評価と呼ばれているのを目にします。 遅延評価のため map, filter は for 文や next 関数 を使って1つ1つ要素を取り出すことはできますが...
m = map(lambda x: 2 * x, range(10))
next(m) # 0
next(m) # 2
next(m) # 4
next(m) # 6
next(m) # 8
next(m) # 10
next(m) # 12
next(m) # 14
next(m) # 16
next(m) # 18
反対に map オブジェクトは、 リストのような lst[0] 添字表記 subscription (opens new window) でいきなり最後の要素を参照したりはできません。 これは next 関数で呼び出されたり、あるいは for 文で呼び出されるたびに計算されているからです。
m = map(lambda x: 2 * x, range(10))
m[9] # TypeError
ちなみに subscription という言葉自体は、 添字式 subscript expression か添字表記法 subscript notation を短縮した Python 独自の用語かと思われます(alc 調べ) (opens new window)。 subscription 自体で購読とかの意味合いはあるのですが、 表記を表す意味合いは alc で調べた限りなさそうでした。
list を返してくれた方がわかりやすそうです。 実際 Python 2 では map はリストを返す関数でした。
>>> # Python 2
>>> map(lambda x: 2*x, [0, 1, 2, 3])
[0, 2, 4, 6]
>>>
短いリストなどメモリを必要としない場合は問題ありません。 しかし、ファイルのような多くのメモリを必要とするものを取り扱ったりするような場合に、 1度に全てをリストにしてしまうと大量のメモリを消費してしまいます。 例えば 10**8 のような長大なリストを生成てみると、1度に大量のメモリが消費されるのがわかります。
import sys
sys.getsizeof(map(lambda x: 2*x, range(10**8)))
# 56
sys.getsizeof(list(map(lambda x: 2*x, range(10**8))))
#815511904 <- リストにすると大量のメモリを消費する。
sys.getsizeof(object[, default]) (opens new window)
オブジェクトのサイズをバイト単位で返します。オブジェクトは、どのような型でも使えます。 全ての組み込み型は、正しい結果を返してくれますが、 サードパーティ製の型は、正しい結果を返してくれるとは限らず、実装によって異なるかもしれません。 属性に直接代入されたオブジェクトが消費したメモリだけ計測され、 属性の属性に代入されたオブジェクトが消費するメモリについては計測しません。
Return the size of an object in bytes. The object can be any type of object. All built-in objects will return correct results, but this does not have to hold true for third-party extensions as it is implementation specific. Only the memory consumption directly attributed to the object is accounted for, not the memory consumption of objects it refers to.
map, filter は、リストではありません。 デメリットは、リストのように途中の値を参照することはできず、すこし使い勝手が悪いです。 メリットはメモリの消費量を抑えることができます。 大量のオブジェクトを取り扱う時に威力を発揮します。
Python の開発者である Guido van Rossum 氏は、map, filter,lambda が嫌いだそうです。 嫌いって言われても... って感じですが、まったく同じ機能を持つ ジェネレータ式 を使って欲しいとのことです。
ジェネレータ式とは何でしょうか?ジェネレータ式は map, filter と全く同じ機能を持ったものです。
lst = [0, 1, 2, 3]
# map
m = map(lst, lambda x: x * x)
list(m)
# ジェネレータ式
g = (x * x for x in lst)
list(g)
lst = [0, 1, 2, 3]
# filter
f = filter(lambda x: x % 2, lst)
list(f)
# ジェネレータ式
g = (x for x in lst if x % 2)
list(g)
ジェネレータ式の詳細については、このさき、以下の記事で見ていきたいと思います。
果たしてどちらを使うべきでしょうか? 基本的には読みやすい方を。 どちらでも良い場合は、Guido は map, filter を嫌っているので、 ジェネレータ式を使った方が良いかなと思ったりもします。
[int(x) for x in row if x != "."]
— ドッグ (@Linda\_pp) November 26, 2018
反対に、既に関数が定義されているようなシーンでは map を使うといいかなと。 簡単に言えば lambda 式を使うくらいならジェネレータ式やリスト内包表記で書いた方が良いかなと思ったりもします。
#
# 対話モード >>> に
# コピペで実行できます。
#
lst = [0, 1, 2,]
def f(x):
return 2 * x
# 0. 元のやり方
# 関数 f を 2 回呼び出しててちょっと嫌だな...
[f(x) for x in lst if f(x) % 2 == 0]
# 1. ジェネレータ式を使った改善例
[y for y in (f(x) for x in lst) if y % 2 == 0]
# 2. map を使った改善例
# 1 より少し綺麗になる
[y for y in map(f, lst) if y % 2 ==0]
# 3. lambda を使った改善例
# なんだか汚くなる
list(filter(lambda y: y % 2 == 0, map(f, lst)))
ちなみに Python 3.8 から 代入式 が使えるようになると、 次のように書けるようになります。
[y for x in lst if (y:=f(x)) % 2 ==0]
結構、嫌われています。以下の文章で、「リスト内包表記」は「ジェネレータ式」に読み替えてください。 以下の文章は Python 2 の頃のもので、その頃はまだ map, filter がリストを返す関数だったためです。
Python における後悔 (opens new window)
私は lambda が、いいと思ったことがない。
- 不自由(たった1行しか書けない)
- 紛らわしい(引数リストの括弧がない)
- 普通の関数定義で代用できる。
I've never liked lambda
- crippled (only one expression)
- confusing (no argument list parentheses)
- can use a local function instead
Python における後悔 (opens new window)
map(), filter()
- Python の関数を使うのは遅い。
- リスト内包表記は同じことをよりよく実行する。
map(), filter()
- using a Python function here is slow
- list comprehensions do the same thing better
リスト内包表記〜ジェネレータ式 -The History of Python.jp (opens new window)
リスト内包表記は、組み込み関数のmap()とfilter()の代替手段となっている。 map(f, S)は、[f(x) for x in S]と同じ意味となるし、filter(P, S)は[x for x in S if P(x)]と同じ意味となる。 map()やfilter()を使った表現の方がコンパクトであるため、 リスト内包表記の方が推奨されていないのでは?と思う人もいるだろう。
しかし、より現実的なサンプルを見ると見解が変わるだろう。 与えられたリストの全ての要素に数字の1が足された、新しいリストを作りたいとする。 リスト内包表記を使った場合には、[x+1 for x in S]と表現できる。 map()を使うと、map(lambda x: x+1, S)となる。 "lambda x: x+1"はインラインで無名関数を作るPythonの書き方である。
ここでの本当の問題はPythonのラムダ記法が冗長すぎることで、 この表記がもっと簡潔になればmap()を使った記法がより魅力的になるはずだ、ということがずっと主張されてきた。 私個人の見解としてはこれには反対である。 リスト内包表記の方が、 特にマップされる式の複雑さが増加するとmap()を使った関数表記よりも見やすくなることが分かったからである。
map 関数, filter 関数とジェネレータ式で、どちらを使うべきか迷ったら、使うのはどっち?
PEP 8 では lambda 式を変数に代入して 使わ無いように定めています。これはなぜですか? 下記のうち適切なものを選択してください。
答え: わかりません... orz
map, filter と for 文の使い分けは、どのようにすれば良いでしょうか? そこで2つの書き方を比較して考えてみたいと思います。 0, 1, ... 9 の整数のうち偶数を 2 倍にした整数のリストを作成していきます。
また本来なら比較対象には map, filter ではなくジェネレータ式とするべきですが、 ここでは map, filter として話を進めます。
new_list = []
for i in range(10):
if i % 2 == 0:
new_list.append(i * 2)
new_list
>>> new_list
[0, 4, 8, 12, 16]
>>>
evens = filter(lambda i: i % 2 == 0, range(10))
duobled_evens = map(lambda i: i * 2, evens)
new_list = list(doubled_evens)
new_list
>>> new_list
[0, 4, 8, 12, 16]
>>>
for 文を 1 回だけ回せば済むところを変数にいれる数だけ、 回さないといけないからです。 例えば for 文で書く方法は 1 度しか for 文を回していません。 対して map, filter を使う書き方では map で 1 回, filter で 1 回の合計 2 回 for 文を回しています。
ただし O(n) の計算量は、問題視されることは、そこまで多くはないのかなと思っています。
この例では分かりにくいですが、 for 文で書くよりも map, filter を使って分割すると、 一般にコードが長くなります。
この例では分かりにくいですが、変数に分割する書き方をするので変数の個数は、 一般に多くなります。 そして変数の個数は一般に少ない方が良いですよね、とされています。
変数を定義した分だけ、それを管理するコストも余分にかかる。これは一つのループ処理などといったごく小さなスコープにおいても当てはまる。ループを回し、条件分岐を重ね、ある場合に更新されるべき変数が更新されていなかったためにバグが発生する、などというケースを私は何度も見てきた。
5. 変数をむやみやたらに作らない - プログラミング中級者に読んでほしい良いコードを書くための20箇条 (opens new window)
ただし変数の個数が多くなってしまうのは、そこまで問題ではないのかなと思っています。 どういうことかというと、結局 for 文を使ってコードが複雑になってしまった場合、 説明するためにコメントを書かないといけなくなるからです。
デメリットが3つもあるのに対して、メリットはたったの1つしかありません。
map, filter で書いたコードは、とてもコメントが書きやすいです。 言い換えれば説明がしやすいです。 なぜなら変数をそのまま読み上げれば、それで何をしているかの作業がわかるからです。
# Step 1. 偶数にして
evens = filter(lambda i: i % 2 == 0, range(10))
# Step 2. 2倍にする。
duobled_evens = map(lambda i: i * 2, evens)
new_list = list(doubled_evens)
new_list
デメリットが3つに対して、メリットが1つしかありません。 ただ、これは個人の感想ではありますが「説明がしやすい」は、 とても大きな要素である気がします。 map, filter を書く書き方は、高速性を下げて、 可読性を上げる書き方だと思っています。
もしその実装が説明しやすいものなら、良いアイディアである。
If the implementation is easy to explain, it may be a good idea.
PEP 20 -- The Zen of Python (opens new window)
また副次的な効果としてネストが浅くなります。
ネストは浅い方が良い。
Flat is better than nested.
PEP 20 - The Zen of Python (opens new window)
null pointer, 制御構文のネスト, 初期のプログラミング言語では、どちらも存在しなかった。 どちらも素晴らしいアイデアとしてプログラミング言語の進歩と評価された。 時代は変わり、null pointer の考案は考案者自身が10億ドルの損失と懺悔し、 ifとforのネストは悪しきコードの典型となった。
— 増田 亨. (@masuda220) October 30, 2019
map, filter を入れ子、ネストして表現すると、何をやっているのかよくわからなるので、 避けた方が良いかなと思っています。
#
# map, filter をネストさせると
# 一瞬でよくわからなくなる。
#
new_list = list(map(lambda i: i * 2, filter(lambda i: i % 2 == 0, range(10))))
new_list
うーん、関数プログラム大好きプログラマーの書くコードは、難読性高い。。。map とかtakeとか catとか何重にも重なっていく。これ自分でも読めるのか?
— 笑い猫 (@bokudentw) May 24, 2019
これは Google のコーディング規約です。 リスト内包表記とジェネレータ式に対するものですが、map, filter に対しても、 同じことが言えるかなと思います。 つまり map, filter を入れ子にはしないで、分割させます。
単純なケースでは使ってもいいよ!
Okay to use for simple cases.
2.7 Comprehensions & Generator Expressions (opens new window)
map, filter は ジェネレータ式と、同じ機能を提供します。ジェネレータ式は、ジェネレータ関数の糖衣構文です。
糖衣構文 - Wikipedia (opens new window)
糖衣構文は、プログラミング言語において、読み書きのしやすさのために導入される書き方であり、 複雑でわかりにくい書き方と全く同じ意味になるものを、よりシンプルでわかりやすい書き方で書くことができるもののことである。 構文上の書き換えとして定義できるものであるとも言える[1]。
Python には他にも糖衣構文として条件式という三項演算子があります。 三項演算子もネストさせると一瞬でよくわからないことになります。 三項演算子もネストは避けた方が良さそうですね。
0 if True else 1 if True else 2
0 if False else 1 if True else 2
0 if False else 1 if False else 2
>>> 0 if True else 1 if True else 2
0
>>> 0 if False else 1 if True else 2
1
>>> 0 if False else 1 if False else 2
2
>>>
複雑な式で三項演算子を使うと、途端にわかりにくくなる。
三項演算子?:は悪である。- Qiita (opens new window)
三項演算子が便利なのは皆知ってるけど、一度ルールを外すと二段三段の三項演算子を書き出す人が出てくる。三項演算子を禁止にしてる理由はそれですね。三項演算子は悪くない。人間が悪い。
— mattn (@mattn_jp) November 6, 2019
リスト list や文字列 str は len 関数で要素の数を数えることができます。
len([0, 1, 2])
len('Hello, world!')
>>> len([0, 1, 2])
3
>>> len('Hello, world!')
13
>>>
WARNING
ここは、重箱の隅をつついているので、軽く読み飛ばしてください。 map, filter を使うと説明しやすいコードになりそうだな、という雰囲気だけ伝わればと思いました。
そのほかにもどのようなオブジェクトが len 関数が使えるのでしょうか? その一覧を取り出すにはどうしたら良いでしょうか? 誰にも聞かれてはいませんが、そんな疑問に答えていきます。
組み込みスコープの名前空間である __builtins__ には
import しなくても使える関数や型がはいっています。
# コピペで実行できます。
print(*__builtins__.__dict__.keys(), sep='\n')
>>> print(*__builtins__.__dict__.keys(), sep='\n')
... 前略
sum
len
tuple
list
... 後略
>>>
>>>
このような関数を難しい言葉で「組み込み関数」、「組み込み型」と言います。 難しく書きましたが、例えば「組み込み関数」には sum や len が該当します。 また、例えば「組み込み型」には tuple や list が該当します。
では早速、
__builtins__ を利用して len 関数で使える型の一覧を取り出してみましょう。
#
# 対話モード >>> に
# コピペで実行できます。
#
# Step1.
# __builtins__ にはいっているオブジェクトを
# リストとして取り出します。
組み込みスコープのオブジェクトのリスト\
= list(__builtins__.__dict__.values())
# Step2.
# __builtins__ には型だけではなく
# 関数もはいっっています。
# Step 1 の結果から関数を取り除きます。
組み込み型のリスト\
= list(filter(
lambda 組み込みスコープのオブジェクト: isinstance(組み込みスコープのオブジェクト, type),
組み込みスコープのオブジェクトのリスト
))
# Step3.
# len 関数で使えるのは
# Step 2 で抜き出したうちの
# __len__ メソッドを持つものだけです。
len関数が使える組み込み型のリスト\
= list(filter(
lambda 組み込み型: hasattr(組み込み型, '__len__'),
組み込み型のリスト
))
print(*len関数が使える組み込み型のリスト, sep='\n')
#
# 変数名を英語で書くなら...
# 処理が分かれてい、説明しやすい
#
# Step 1. 組み込み型の一覧を取り出す。
builtin_types\
= (cls for cls in __builtins__.__dict__.values() if isinstance(cls, type))
# Step 2. イテラブルな組み込み型の一覧を取り出す。
builtin_iterbale_types\
= (cls for cls in builtin_types if hasattr(cls, '__iter__'))
# Step 3. イテラブルな組み込み型の一覧を表示する。
print(*builtin_iterbale_types, sep='\n')
>>> print(*len関数が使える組み込み型のリスト, sep='\n')
<class 'memoryview'>
<class 'bytearray'>
<class 'bytes'>
<class 'dict'>
<class 'frozenset'>
<class 'list'>
<class 'range'>
<class 'set'>
<class 'str'>
<class 'tuple'>
>>>
これを純粋な for 文で書き換えてみると以下のようになります。
#
# 対話モード >>> に
# コピペで実行できます。
#
len関数が使える組み込み型のリスト = []
for 組み込みスコープのオブジェクト in __builtins__.__dict__.values():
if isinstance(組み込みスコープのオブジェクト, type) and hasattr(組み込みスコープのオブジェクト, '__len__'):
len関数が使える組み込み型のリスト.append(組み込みスコープのオブジェクト)
print(*len関数が使える組み込み型のリスト, sep='\n')
#
# 変数名を英語で書くなら...
# 処理が1つにまとまっていて説明しにくい。
#
builtin_iterbale_types = []
for cls in __builtins__.__dict__.values():
if isinstance(cls, type) and hasattr(cls, '__iter__'):
builtin_iterbale_types.append(cls)
print(*builtin_iterbale_types, sep='\n')
>>> print(*builtin_iterbale_types, sep='\n')
<class 'bytearray'>
<class 'bytes'>
<class 'dict'>
<class 'enumerate'>
<class 'filter'>
<class 'frozenset'>
<class 'list'>
<class 'map'>
<class 'range'>
<class 'reversed'>
<class 'set'>
<class 'str'>
<class 'tuple'>
<class 'zip'>
>>>
本節は以上になります。 説明しやすいコードになりそうだな、という雰囲気だけ伝わればと思いました。
こんな嫌われているもの、いったいどういう経緯で組み込まれたのでしょうか? Lisp という別のプログラミング言語から、まとめて輸入された書き方のようです。
12 年前に Python は lambda, reduce, filter そして map を獲得した。 礼儀正しい(と私は信じている)Lisp のハッカーが lambda, reduce, filter, map が恋しくなり working pathces を提出した。
About 12 years ago, Python aquired lambda, reduce(), filter() and map(), courtesy of (I believe) a Lisp hacker who missed them and submitted working patches.
The fate of reduce() in Python 3000 by Guido van van Rossum (opens new window)
map, filter, lambda 以外に reduce という文字が見えます。reduce とは何をしてくれる関数でしょうか? ちなみに嫌われ過ぎて組み込み関数から削除された重要度の低い関数なので、覚える必要はあまりないかなと思います。
3. reduce ... リストの要素を 関数を元に累積 します。

リストの要素を関数を元に累積します。
# 総乗を求めます。
from functools import reduce
def mul(x, y):
return x * y
lst = [1, 2, 3, 4, 5, 6, 7]
product = reduce(mul, lst)
print(product)
>>> print(product)
5040
>>>
ちなみに reduce は、関数を引数に取るので高階関数になります。
Python 2 では reduce 関数が、組み込み関数として使えました。 Python 3 では reduce 関数は、組み込み関数 (opens new window) から除外されて 標準ライブラリ (opens new window) の1つである functools から import することになりました。
import しないと使えなくなったということは1軍から2軍に格下げされたということです。 なぜ格下げされたかと言うと読み辛いからだそうです。
reduce()
- 誰も使ってない、少しの人しか理解してない。
- for ループの方が理解しやすいし、たいていの場合速い
reduce()
- nobody uses it, few understand it
- a for loop is clearer & (usually) faster
The fate of reduce() in Python 3000 by Guido van van Rossum (opens new window)
今度は reduce 関数について考えよう。これは実際私がいつも最も憎むものだ。+ もしくは * を含む2、3の例を除けば reduce 関数はいつもパッと見ではわからないような関数を引数にとって呼び出されている。
So now reduce(). This is actually the one I've always hated most, because, apart from a few examples involving + or *, almost every time I see a reduce() call with a non-trivial function argument,私は reduce 関数が何をしているかを理解する前に、引数として与えられた関数に、実際に何が与えられているのかを図示するために紙とペンを取らないといけない。
I need to grab pen and paper to diagram what's actually being fed into that function before I understand what the reduce() is supposed to do.したがって私の中では reduce 関数が適用できるのは、結合演算子にごく限定される(訳注: 結合演算子 ... 例えば +, -, *, / などの四則演算子)。それ以外の事例では明示的に累積ループを書いた方がよい。
So in my mind, the applicability of reduce() is pretty much limited to associative operators, and in all other cases it's better to write out the accumulation loop explicitly.
#
from functools import reduce
lst = [1, 2, 3, 4, 5]
# 1. 明示的に累積ループで書く
def sum(s):
p = 1
for e in s:
p = p + e
return p
sum(lst) # 120
# 2. reduce で書く
reduce(lambda x, y: x + y, lst) # 120
# 3. Python2 では import しなくても書けた
# reduce(lambda x, y: x + y, lst) # 120
# reduce で最大値を求めてみる。
from functools import reduce
lst = [3, 4, 5, 1, 2, 0]
# 1. 明示的に累積ループで書く
def max(lst):
x = lst[0]
for y in lst:
if x <= y:
x = y
return x
max(lst) # 5
# 2. reduce で書く
reduce(lambda x, y: x if x > y else y, lst) # 5
# 3. Python2 では import しなくても書けた
# reduce(lambda x, y: x if x > y else y, lst) # 120
Python では reduce を使うことなく、組み込み関数として min, max, sum を使うことができます。 よく使うものは組み込み関数に入れる、使わないものは入れないというバランス感覚も、 やはり Guido は絶妙だなと思ってしまうのです。
The fate of reduce() in Python 3000 (opens new window)
reduce と関連のある演算子は多くはない (関連のある演算子 X というのは (a X b) X c と a X (b X c) が等しくなるようものだ)。 私は +, *, &, |, ^ などにごく限定されると思う。 Python には、すでに sum 関数がある。 もしやらねばならないのなら reduce 関数を捨てて product 関数を喜んで入れる。 +, * という reduce 関数の最も一般的な2つの使用例に対処するために。
There aren't a whole lot of associative operators. (Those are operators X for which (a X b) X c equals a X (b X c).) I think it's just about limited to +, *, &, |, ^, and shortcut and/or. We already have sum(); I'd happily trade reduce() for product(), so that takes care of the two most common uses.
上記の Guido のブログを読んでいると Guido が map, filter, reuduce を組み込み関数から絶対に外すマンになっていてちょっと面白いです。 誰にどう説得されたのかわからないのですが、map と filter は残りました。
徐々にエスカレートしていくwindows10アップグレードちゃんの様子 pic.twitter.com/FvqjXzjfKJ
— ponz(透) (@ponzholic) May 18, 2016
map, filter は関数型言語である lisp から輸入されました。 では 関数型言語とは何者なのでしょうか? 関数型言語にはいくつか特徴があるそうですが、 ここではただ1点「参照透過性」ということを まず押さえておけばいいのかなと思います。
関数型言語は、 参照透過性 (opens new window) を前提にした言語です。 「参照透過性」というのは、関数に引数を与えて実行したときに必ず結果が一意に定まることを指しています。
関数型プログラミングとは Referential Transparency を徹底的に追求するプログラミングです ... 後略
megumin1 氏のブクマ (opens new window)
参照透過性を担保するには、副作用のないコードを書かないといけません。 副作用 とは、 簡単に言えば、変数や属性に1度代入したら、再代入はできないということです。
for 文を使わないとはどういうことでしょうか? 例えば、与えられたリストの和を計算する関数を考えます。
def sum(lst):
s = 0
for e in lst:
s += e # <--- 変数 s に再代入しています。
return s
sum([3, 1, 0, 2, 4])
>>> sum([3, 1, 0, 2, 4])
10
>>>
と、言う具合に変数への再代入が発生してしまうので、 map, filter, reduce を組み合わせていきます。
from functools import reduce
def sum(lst):
return reduce(lambda a, b: a + b, lst)
sum([3, 1, 0, 2, 4])
>>> sum([3, 1, 0, 2, 4])
10
>>>
ここで「参照透過性」があることがわかっていると、 一度計算したことについては、引数と返り値をセットにしておけば、 再計算をする必要がなくなるということです。
このような高速化の技法を メモ化 (opens new window) とか言われるのを目にします。 標準ライブラリ functools のなかにある lru_cache (opens new window) は、 このメモ化の機能を提供してくれます。
Python の標準ライブラリの中に、関数型プログラミング用モジュールというのがあります。 lru_cache や reduce が封印された functools は関数型プログラミング用モジュールの中に分類されています。
ちなみに完全に「参照透過性」を担保しようとすると、 「関数型言語」でも、結構大変だったりするらしいです。 「状態」を持たせないこと自体結構大変だったりするのかもしれません。
参照透過性を厳密に担保している Haskell とかとてもいい言語らしく、ぜひ触ってみたいのですが、 あまり実地で使われているという話を聞いたことがありません。
純粋関数型言語である Haskell は、とても言語として素晴らしいらしく、 自分もいつかぜひ触ってみたいと思ってはいるのですが、 現場での採用という例はあまりないようです。 副作用を絶対に認めないというのは、やはりちょっと厳しい気がします。
関数型言語でも副作用を認めてくれる Elixir などは、 あまりどれくらいの浸透度合いなのかわからないのですが、 コミュニティが盛んなのを Twitter でよく見かけます。
たまに「オブジェクト指向はオワコン、 これからは関数型言語の時代や」という言及を目にします。 このように言及されている時のオブジェクト指向は、 たいていの場合、「副作用」かもしくは「継承」のことを指しているのかなと思われます。
「副作用」も「継承」も一般には避けた方が良いことはわかるのですが、 オブジェクト指向の考え方そのものを否定するものでは無いのかなと思ったりします。 関数型言語は、オブジェクト指向の一種で、 再代入を許さないオブジェクト指向言語だと個人的に思っています。
PyCon の動画を見つけました。引用したものの一切理解していません...
純粋な関数型言語の特徴として、間違っているものは、どれですか?
ここまで以下のように見てきました。
最初に map, filter, lambda の基本的な機能について触れてきました。
map, filter の落とし穴について触れて、 map, filter から生成されるオブジェクトは、リストではないことを見てきました。
next 関数を使い map, filter オブジェクトに実際に触れて、 リスト lst[0] のように添字表記では参照できず使い勝手が悪い反面、 省メモリではあることを見てきました。
map, filter はジェネレータ式と全く同じ機能を有しています。 Guido は map, filter が嫌いなので、どちらを使うか迷ったら ジェネレータ式を使うようにするのがいいかなと思います。
map, filter, lambda を使って for 文を分割して書く方法を見てきました。 map, filter の由来を調べ、 reduce を通して組み込み関数 (opens new window)は1軍、 標準ライブラリ (opens new window)は2軍と言った 温度感についても簡単に触れました。
最後に map, filter 式の輸入元である関数型言語の特徴についていくつか触れました。 以上になります。ありがとうございました。