
map と filter
関数型言語 Lisp 由来の関数です。ちなみに Guido は嫌いらしいです。
ウラキ少尉で学ぶ、新入社員の1年 pic.twitter.com/78cYUTJxkg
— ぴーぴー🍟 (@pp028_KarenP) April 2, 2018
「副作用」とは、関数またはメソッドを実行した時に、オブジェクトの属性が変化することを指しています。 例えば Python の list.sort は、副作用のあるメソッドです。 反対に sorted は、副作用のない関数です。
#
# 副作用あり
#
lst1 = [1, 0, 3, 2]
lst1.sort()
lst1
# [0, 1, 2, 3] -> オブジェクトが変化したので副作用がある
#
# 副作用なし
#
lst2 = [1, 0, 3, 2]
lst3 = sorted(lst2)
lst2
# [1, 0, 3, 2] -> オブジェクトは変化していないので副作用はない
lst3
# [0, 1, 2, 3]
プログラミングにおける副作用(ふくさよう)とは、ある機能がコンピュータの(論理的な)状態を変化させ、 それ以降で得られる結果に影響を与えることをいう。代表的な例は変数への値の代入である。
副作用 - Wikipedia (opens new window)
副作用がないと思っていたのに、実は副作用があったりすると、 障害につながります。 深夜にベンダーさんの作業を立ち会いしていました。 大量の障害報がビービー鳴り響きました。 最初はどこかで作業しているんだろうくらいに思っていました。
どうやら大規模障害が発生したらしいことがわかりました。 僕は立会でしたが、そんな影響の大きい範囲の作業は、うちくらいしかしていなかったので、 ついにこの時が来てしまったか、という気持ちでいっぱいになりました。
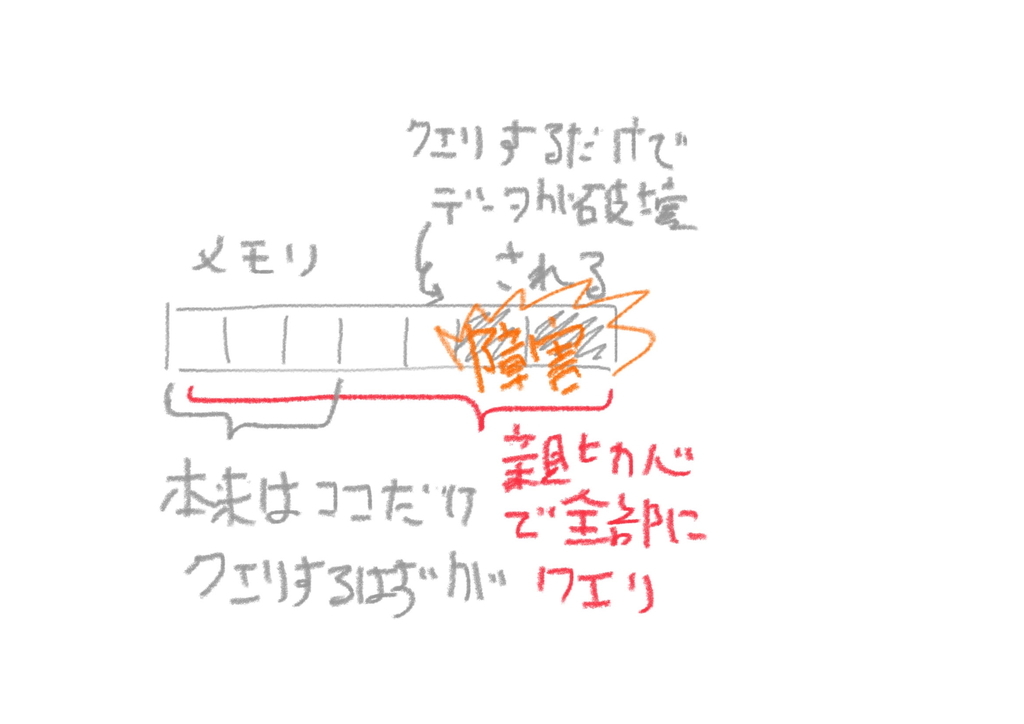
でも、どうやら、ある別のベンダーさんの装置に限定された障害であることがわかり、 自分たちの作業ではないことがわかりました。後日わかった原因は、 メモリのある特定の箇所を確認するクエリコマンドを打つと、設定が変わってしまうアクションコマンドも混じっていたという仕様が原因らしく...
書き込まれたデータを読み出す時に、内容を破壊してしまうものが破壊読み出しである。
破壊読み出しと非破壊読み出し - Wikipedia (opens new window)
その作業手順書には、該当箇所のメモリは参照するなと書かれていたけど、 作業をしていた方が親切心で事前確認のために、当初指定されていた範囲よりも広い範囲の、 クエリコマンドをかけてはいけないと手順書に記載されていた箇所も含めて、 全国にある数千の装置に同時にクエリコマンドを打ち込んで大規模障害が発生したようでした。
僕、個人は、その人が悪いとは一切思いません。むしろ、日々限られた時間の中で作業手順を組み、 作業に望むことは何があるかわからない恐怖心との戦いで、エクストリームスポーツそのものでした。 本当に毎日お先真っ暗感いっぱいの中で仕事をしていました。
大量の機器、あるいは設定を取り扱わないといけない中で、 作業前にクエリコマンドを打ちまくって機器の状態を確認することは、 機器を自分の体の一部のようにすることは、 褒められることではあっても貶されることではないと思います。これは私のポジショントークかもしれませんが。
実際に設定が正しいことを確認するには、手順書を作成した時とは別の視点で確認することが大切です。 同じ視点で見ても誤りに気づくことができないからです。 例えば、エクセルの管理表で手順書を作り、その手順書が正しいかどうかの確認は、現地の示名条片で確認します。
また確認するときも、全てを確認することはできないので、絶対に間違えてはいけないところだけを、優先的に確認します。 間違えてはいけないところとは、事前に申請していたサービス断以上の箇所に影響が及ぼす過ちです。 事前に申請した範囲内のサービス断の中での誤りであれば、 初めてみるエラーを、黙ってその場で修正してました。 これは地味に堪えました。
もちろん手順書を熟読しなかったことは悪いことですが、絶対に起こり得るヒューマンエラーだと思います。 その人がやらなかったとしても別の人がやることを、私は確信しています。
ちなみにこの時の改善策は「検証していないコマンド、手順書に書かれていないコマンドは打たない。」 となり、監督機関に報告していました。何も対処できていません。 負担だけが増えました。数年に経ったら、 ワイルドカードを記載した手順書が仕上がってくるのが目に見えています。
必要に応じ任意のクエリコマンドを打ち込む
クエリコマンド ワイルドカード show memory *
ここでの正しい改善策は「副作用のある操作」と「副作用のない操作」を明確に分けることです。 機器の選定時にベンダに問い合わせ、それを確認することです。 なんで人力で頑張るが改善策なのでしょうか。
| 副作用 | 可読性 | 実装面 (メモリ) | 実装面 (速度) | あり | X | O | ? |
|---|---|---|---|
| なし | O | X | ? |
根拠があるわけではなく全て主観です。 可読性は、副作用がない方が、良いことが多いような気がします。 実装面(メモリ)は、副作用があった方が、良いです。 実装面(速度)は、わからない、ケースバイケースかなと思います。
副作用がない方が速くなるよ。と書かれているのをよく見かけるのですが、 常にそうとはちょっと言えないのかなと個人的に思っています。
以下、まず「副作用がないことのデメリット」を1つだけ挙げます。 次に「副作用がないことのメリット」を大量に挙げています。 副作用があることが、何か論理的に悪いというわけではないかなと思います。 あくまでも経験則です。
たまたま、いま生きている世界線が、 たまたま、副作用があると辛いということがなんとなくわかって来たということで、 大量に「副作用がないことのメリット」を挙げています。
頭のおかしいやつがなんか言ってるな、くらいの適当な感じで読み流していただけると嬉しいです。
一切、再代入を許さないとなると、 都度オブジェクトを生成しないといけなくなります。 すると、メモリの消費量の面で苦しくなりやすい気がします。
生成のコスト(というか手間)もありますが、例えばエクセルのスプレッドシートみたいなインタラクティブなオブジェクトを本当に不変オブジェクトで表現できるのかという感じもします(fusion_placeにもそんなオブジェクトがあります)。コストではなく向き不向きがあるのでは、という話です。
— 杉本啓 (@sugimoto_kei) November 5, 2019
Haskell は、 純粋関数型言語 (opens new window) に分類されるプログラミング言語です。 平たく言えば、変数や属性への再代入をかなり厳しく許してくれないそうです。 Haskell 自体は色々なところでプログラミング言語として、好意的に評価されているのを見かけます。
自分も触りたいです。触れる人生でありたかったです。 これが理想形のような気もするのですが、やはり絶対に副作用を許さないとなると結構厳しいのか、 Haskell そのものがプロダクトとして積極的に採用されている気配はありません。
関数型言語でも副作用を認めてくれる Elixir などは、 あまりどれくらいの浸透度合いなのかわからないのですが、 コミュニティが盛んなのを Twitter でよく見かけます。
副作用を持つとテストが面倒になります。 以下の現在時刻が関わるテストは、とても面白かったです。
例えば Python の str は immutable です。 なぜ Python の str が immutable なのかという記事を見つけました。
なぜ Python の文字列はイミュータブルなのですか? - Python よくある質問 (opens new window)
これにはいくつかの利点があります。
一つはパフォーマンスです。文字列がイミュータブルなら、生成時に領域を割り当てることができるので、 必要な記憶域は固定されて、変更されません。 これはタプルとリストを区別する理由の一つでもあります。
...後略...
#
# 注釈
# str が immutable であるとは
#
s = "ランボー/怒りの脱出"
# 1文字ずつ参照できます。
s[0]
s[1]
s[2]
s[3]
# 代入はできません -> immutable です。
s[0] = 'チ'
>>> # 1文字ずつ参照できます。
... s[0]
'ラ'
>>> s[1]
'ン'
>>> s[2]
'ボ'
>>> s[3]
'ー'
>>>
>>> # 代入はできません -> immutable です。
... s[0] = 'チ'
Traceback (most recent call last):
File "<stdin>", line 2, in <module>
TypeError: 'str' object does not support item assignment
>>>
immutable であると実装が容易になります。 容易である分、実行する速度も速くなるというのは、なんとなくわかる気がします。 例えば Python は、オブジェクトの属性は mutable で自由に付け足しできたりします。 とても便利そうです。しかし、そういった便利さのために属性参照が鬼のように重くなっています。
ここはかなり自分の理解が怪しいです。怪しいなら書くなよ... という話なのですが... Rust は、とても厳密に mutable を管理します。 この記事は、後半は厳しいですが、前半は、わかりやすいです。
なんでこんな muutable を厳密に管理しているかというと、 ガベレージコレクションでのゼロコストを狙って、mutable を厳密に管理しているらしいです。 使わなくなったオブジェクトを破棄しないとメモリが一杯になって動作が重くなってしまいます。 ガベレージコレクションというのは、使わなくなったオブジェクトを破棄する機能です。


あまり詳しいことは知りませんが、 実装面での恩恵を受けつつ、副次的に可読性の点でも恩恵を受けているという、 なかなか素敵な実装になっているらしいです。
そうなんですよ、 「状態を全て値として持てばプログラムの局所性を担保できる」をやりきったのがHaskellなのに対して、 「状態を参照で持ち回しても、その排他性を正しく管理すればプログラムの局所性を担保できる」という形で実現してしまったのがRustなんですよ。
— Masaki Hara (@qnighy) October 14, 2018
ここ 5.4 から 5.5, 5.6, 5.7 までは可読性の話になります。 副作用が無ければ、影響範囲を絞ることができます。
副作用がない関数だとわかっている場合、システムに影響を及ぼす範囲は、 関数の返り値の中にに限定されます。 引数と返り値だけに注目しておけば良いです。 関数の返り値の構造が大き過ぎたら、あまり意味がないのですが笑
反対に副作用がある関数だとわかっている場合、システムに影響を及ぼす範囲は、 パッとコードを見ただけでは、どこまで影響があるのか判断ができません。 ドキュメントあるいは最悪コードを読まないと影響範囲がわかりません。
副作用がある関数は、どこまでその関数がシステムに影響するのか、 把握するか、あるいは覚えておかなければなりません。 副作用のあるコードは、影響範囲の広い、コードを読む人の脳への負担、 ワーキングメモリへの負担が大きいコードだと言えます。
C# の記事になってしまうのですが ミュータブルな List ではなく イミュータブルな IReadOnlyList を使えと怒っている記事を見つけました。 とても勉強になります。
ミュータブルなリストを使うとなにが問題なのでしょうか。 この記事のテーマ、副作用の点から言えば、 想定していなかった箇所が変化してしまうかもしれないことが問題かなと思っています。
Items の型が
List<T>なので当然AddしたりRemovePしたり出来てしまう。 そんなことをすると、クエリーの結果が改ざんされてしまうことになり、 そのようなことが起こることを予期していない他の開発者のコードでバグ(というか予期しない動作)が多発するだろう。 いくら、コーディングルールや、チーム内の暗黙知として、「Itemsを変更するな」といった取り決めがあったとしても、 実際に変更可能な実装になっている限り、不安は付きまとう。人間はミスをする。
引数の型を何でも List にしちゃう奴に... - Qiita (opens new window)
マルチスレッドを自分は理解していません。 複数の関数を同時に実行したい時があるそうです。 で、その複数の関数から、 ある1つの mutable なオブジェクトを変更する処理がはいっていたらどうでしょうか?
一体いつ誰が、どこで変更するのかを気にしないといけなくなります。 immutable に設計しておけば、そういった心配もありません。 下記の記事は JavaScript の記事ですが、勉強になります。
イミュータブルの利点は、挙動が予測可能なところです。 物事が単純になり、見通しが良くなります。 また、JavaScriptではあまり恩恵を受けられませんが、イミュータブルにすると自動的にスレッドセーフが実現できます。
JavaScriptでイミュータブルなプログラミングをする (opens new window)
イミュータブルなオブジェクトはマルチスレッドプログラミングにおいても有用となる。 データがイミュータブルなオブジェクトで表現されていると、 複数のスレッドが他のスレッドにデータを変更される心配なくデータにアクセスできる。 つまり排他制御の必要がない。よってイミュータブルなオブジェクトのほうがミュータブルなものよりスレッドセーフであると考えられる。
イミュータブル - Wikipedia (opens new window)
繰り返しになりますが str は immutable です。 もし str が mutable だった場合、 想定していなかった箇所が変化してしまうかもしれない、ということが起こります。
「他の利点は、Python の文字列は数と同じくらい "基本的" なものと考えられることです。」とは、 何を指しているのでしょうか?
なぜ Python の文字列はイミュータブルなのですか? - Python よくある質問 (opens new window)
これにはいくつかの利点があります。
... 中略 ...
他の利点は、Python の文字列は数と同じくらい "基本的" なものと考えられることです。 8 という値を他の何かに変える手段が無いように、文字列 "eight" を他の何かに変える手段も無いのです。
恐らく 辞書のキーとして使いたい ということだと思われます。
#
# 偽物の Python
#
name = '名前'
gender = '性別'
person = {name: '鈴木', gender: '男'}
print(person['名前'])
# 鈴木
#
# もし str が mutable だったら...
#
name[0], name[1] = '苗', '字'
print(person['苗字'])
# ^^^^ 辞書のキーが名前から苗字に変わってしまう...
# 鈴木
こんなの当たり前だろって感じだし、だからなにって感じなのですが Python の「属性」も「ローカル変数、グローバル変数」も、辞書で実装されています。
from pprint import pprint
a = 0
pprint(globals())
class C:
d = 2
pprint(C.__dict__)
>>> # 簡単のため色々と削除しています。
>>>
>>> class B:
... c = 2
...
>>> pprint(B.__dict__)
mappingproxy({'c': 2}) # <--- c をキーに持つ辞書
>>>
この辞書のキーになる文字列が mutable で自由に書き換えられると、ちょっと怖いなという感じがします。 どういうことが起こるかというと、同じ変数名でも参照できなくなってしまいます。 以下のようなコードが実行できてしまうのです。
#
# 偽物の Python
#
a = 0
#
# どうでもいいコード
#
local_scope = locals()
name_a = next((key for key in locals().keys() if key=='a'))
assert name_a == 'a'
# ここにだけ注目してください!
# ローカルスコープの変数の名前が
# b = 'a'; del a;
# と書かずに辞書を通して
# 書き換わってしまったということです。
name_a['0'] = 'b'
assert b == 'a'
>>> # もちろん 本物の Python に
>>> # コピペすると弾かれます。
>>> name_a['0'] = 'b'
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'str' object does not support item assignment
>>>
もちろん代入すれば変数の名前なんていくらでも変えられるのですが、 こうして辞書を通して変更されると、コードを鬼のように読みづらくなります。
そんなことをするやついるのかよ?って感じですが、 使える機能は使いたおしたくなるのが人情ですし、 すごい人たちは多分使ってしまうんだと思います。
そしてこれどうなってんの?と思ってコードを読もうと思っても追えなくなてしまう みたいな感じになるんだと思います。 メタクラス は、そう言ったコードを追いにくくする代表的な機能だと思っています。
強力な機能
このような機能は避ける。定義: Python はとても柔軟な言語であり、 メタクラス、バイトコードへのアクセス、 高速コンパイル、動的な継承、オブジェクトの親の変更、インポートハック、リフレクション、 内部システムの変更 など多くの素敵 (変態的) な機能があります。
ちなみに辞書のキーは mutable で、実装できないことは無いけど、 完全に自己責任でやってなみたいなことが公式ドキュメントで書かれています。
なぜ辞書のキーはイミュータブルでなくてはならないのですか? - Python よくある質問 (opens new window)
必要ならばこれを回避する方法がありますが、自己責任のもとで行ってください。 ミュータブルな構造を、 __eq__() (opens new window) と __hash__() (opens new window) メソッドの両方を持つクラスインスタンスに含めることができます。
安全な辞書のキーとしても使いたいし、 文字列を部分的に切り抜いて書き換えることはあまり無いというという2点を考慮して、 str を immutable にしたという意思決定なのかなと思ったり思わなかったりします。 Quora も見かけたので、リンクを貼っておきます。
immutable のメリットは2つあります。 可読性と、実装面です。 個人的には可読性が主で、実装面は副かなと思ったりもします。
immutable なオブジェクトの実装は、単純になります。 immutable なオブジェクトを使用する側の実装は、メモリを潤沢に消費するような書き方をせざる得なくなります。 すると、この2つの背景の中で、処理速度が速くなるときもあります。 しかしメモリの消費量は、確実に悪化します。
これらのことを踏まえると 副作用がないことは人間にとってはメリットですが、 機会にとってはデメリットかなと思います。 静的型付けについても同じような指摘があります。
自分の未熟さをカバーするために、型システムがあるんですよ > id: yug1224 。 未熟だからミスが起きた、根性でテスト書けばなんとかなる、 という一部の動的型付け言語ユーザーの精神論はまさにブラック企業の体質と同じ。
megumin1 氏のコメント 2018/06/03 21:00 (opens new window)
「副作用がない(関数型プログラミング)」、「静的型付け」、「非同期」の3つが、 ここ最近の言語の流行りかなと思っています。 ここで面白いのは、唯一非同期だけは、可読性が悪化してでもパフォーマンスを得ようとしています。
ごく軽くではありますが Haskell, Java と Rust については、触れてきました。
ここでは JavaScript について見てみます。
ちなみに JavaScript は、Chrome にコピペで実行できます。
属性ではなく変数、定数の話になりますが、
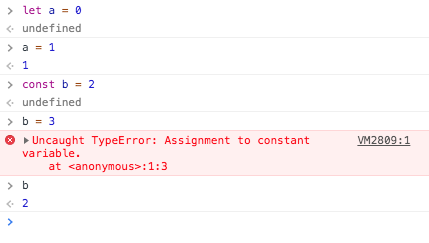
ES6 で const が導入されました。定数が宣言できるようになりました。
let a = 0
// undefined
a = 1
// 1
const b = 2
// undefined
b = 3
// TypeError
b
// 2
1 行ずつコピペすると以下のようになります。
Qiita などの記事で勉強させていただいていると
let ではなく const を使おうという文言をよく見かけます。
Python で属性と呼ばれているものは、JavaScript ではプロパティと呼ばれています。 プロパティを変更できないようにすることはできるのでしょうか? Object.freeze() を使うとできます。
ただ const で再代入しようとエラーで弾き返されるのに対して、
//
// JavaScript
//
const a = 1
// undefined
a = 2
// Thrown:
// TypeError: Assignment to constant variable.
Object.freeze されたオブジェクトのプロパティに、 再代入しても特にエラーも返されません。 プロパティの値は変化しませんでした。
//
// JavaScript
//
const obj = {
prop: 42
}
// undefined
Object.freeze(obj)
// { prop: 42 }
obj.prop = 33 // <--- 再代入の操作は、できてしまう....
// 33
obj.prop // <--- でも、値は変化しない
// 42
また const の温度感は高いですが freeze を使おうという温度感は高くありませんというか、見たことがありません。
結局 Java と同じで頑張ったら immutable にできるというのは、受け入れられないのかなと感じています。
CQS では、コマンドとクエリを分けることで副作用のある処理を明示しました。 しかし、ウェブ系のサービスを作るときに CQS を適用して HTTP リクエストをクエリとコマンドに分けるのは、 面倒なわけです、負荷の問題もあるのかもしれません。 ここで GraphQL を見てみたいと思います。
まずGraphQLとは何でしょうか。 GraphQLは、Facebookが開発しているWeb APIのための規格で、「クエリ言語」と「スキーマ言語」からなります。
「GraphQL」徹底入門 - エンジニアHub (opens new window)
英語になってしまうのですが、以下に playground と動画があります。 動画を見ながら playground で遊んで触った方が理解が速いかなと思います。 副作用のない Query と副作用のある Mutation に、 別れていることに注目してください。
React は Facebook 製の JavaScript フレームワークで immutable なプログラミングと相性が良さそうな気配があります。
元々関数型プログラミング由来の React では、class コンテナのような状態の塊は嫌われる。class 作った瞬間に state 以外の暗黙の状態を作られることを、Reactをよく理解した上級者は嫌ってる。副作用を起こす手続きを限定することでコードの見通しをよくしたい、のが hooks の動機
— 限界シェアハウスみたいなTL (@mizchi) April 26, 2019
答え: Python では、そもそも immutable にすること自体、あまり意味がない気がします。
immutable は重要そうです。にも関わらず、なんで意味がないのでしょうか。 なぜなら Python は、可読性においても、実装面においても、あまり immutable の恩恵に預かれないと思うからです。 実装の仕方はこちらにまとめました。
まず第一に、可読性、副作用の面で言えば、例えば Rust のようにほとんど immutable で部分的に mutable ですよ、 とするなら、コードを書く人の脳への負担が少ないコードがかけると思います。 mutable な箇所は限定されているので、そこにだけ注意してコーディングすればいい訳です。
反対に Python では、ほとんどすべてのオブジェクトが mutable ですし、定数を宣言することさえできません。 そのような中で mutable な箇所はどこかを意識するのは無理がありますし、 逆にこれが immutable だから安心というのも無きにしもあらずですが、効果は限定的な気がします。
また第二に、さらに悪いことに、実装面で言えば、ユーザ定義クラスを頑張って immutable にしても、 「属性参照」や「インスタンス化」にかかる速度がもれなく遅くなります。 immutable_metaclass.py は、読む必要はありません。後述します。
$ python immutable_metaclass.py
### 時間計測
# 属性参照
普通のクラス 0.07876141
__slots__ を使ったクラス 0.07551351699999999
namedtuple を使ったクラス 0.10180483000000001
Immutable メタクラスを使ったクラス 0.08366162300000002
# インスタンス化
普通のクラス 0.48623005900000005
__slots__ を使ったクラス 0.41285596299999994
namedtuple を使ったクラス 0.5147371169999999
Immutable メタクラスを使ったクラス 0.9039751979999999
$
なぜ、このようなことが起こるのでしょうか? immutable は実装が簡単で処理性能が上がるのではなかったのでしょうか。
それは Python の属性がデフォルトで mutable なので、 それを immutable を実装しなおさないといけません。 そして、そんな面倒なことを実行しているので「属性参照」の速度が遅くなっているという訳です。
namedtuple を使うと immutable なクラスが作れます。 どのような原理で namedtuple が immutable なクラスを生成しているか、こちらで見てきました。
ちなみに namedtuple は tuple を継承したクラスを生成するので メモリの消費量については改善されるかと思います。
自分でも「属性参照」と「メモリ」を改善した immutable なクラスを実装しようと足掻いては見ました。 結局、速度を改善することはできませんでした。 「属性参照」を改善した immutable なユーザ定義クラスを実装しようとしたのですが、失敗しました。
どう失敗したのかと言うと、「属性参照」は改善したのですが、 「インスタンス化」するときの速度が重くなり過ぎてしまいました。 失敗したと言うことだけ示すためにコード immutable_metaclass.py を添付しました。 失敗したコードなので、見ていただく必要は全くありません。 計測したので貼り付けました。
immutable なクラスを実装することは、あまり効果がなさそうなことを見てきました。 では、どのようにして副作用と向き合っていけばいいのでしょうか。
堅牢なアプリケーションを実現する上で「副作用を最小限に抑える」という設計思想は、 非常に重要な示唆を含んでいます。
副作用を最小限に抑えるために必要なこと - かとじゅんの技術日誌 (opens new window)
なるべく副作用を作らない。 副作用がある処理、値を作る場合は、それ明示することが大事かなと思いました。
1 は Command-query separation と呼ばれるものです。ちゃんとしたものなので、ググると色々と情報が出てきます。 2, 3 は自分の妄想なので信用しないでください。
「あらゆるメソッドは、アクションを実行するコマンドか、呼び出し元にデータを返すクエリかのいずれかであって、両方を行ってはならない。 これは、質問をすることで回答を変化させてはならないということだ。」とは、どういうことでしょうか?
CQS: 「あらゆるメソッドは、アクションを実行するコマンドか、 呼び出し元にデータを返すクエリかのいずれかであって、 両方を行ってはならない。これは、質問をすることで回答を変化させてはならないということだ。」
副作用を最小限に抑えるために必要なこと - かとじゅんの技術日誌 (opens new window)
もう一度、ソートの処理を見ます。list.sort メソッドは、何も返しません(正確には None を返しています)。 もし乱暴に言うなら "副作用のある関数に返り値を持たせるな、副作用のない関数には返り値を持たせろ" ということです。
# 副作用あり
lst1 = [1, 0, 3, 2]
lst1.sort()
lst1
# [0, 1, 2, 3] -> オブジェクトが変化したので副作用がある
# 副作用なし
lst2 = [1, 0, 3, 2]
lst3 = sorted(lst2)
lst2
# [1, 0, 3, 2] -> オブジェクトは変化していないので副作用はない
lst3
# [0, 1, 2, 3]
副作用のあるコマンドには返り値を持たせないことで、副作用の有無を明示することができます。 もし、実行結果が知りたければ、アクションコマンドとは別にクエリコマンドを投げるべきです。 もし、処理が失敗したなど何か特別なことを通知したければ、返り値を返さずに失敗したことを通知するために例外を投げるべきです。 うっかりなんて大げさな、と思っていました。
パフォーマンスが問題となる状況では、ソートするためだけにリストのコピーを作るのは無駄が多いです。 そこで、 list.sort() はインプレースにリストをソートします。 このことを忘れないため、この関数はソートされたリストを返しません。 こうすることで、ソートされたコピーが必要で、 ソートされていないものも残しておきたいときに、 うっかり上書きしてしまうようなことがなくなります。
なぜ list.sort() はソートされたリストを返さないのですか? - Python よくある質問 (opens new window)
副作用のあり、なしを返り値のあり、なしで明示することを見てきました。 では、副作用がどこで起こるかを明示するにはどうしたらいいでしょうか? 例えば RPG ゲームのプライヤーがモンスターに攻撃することを考えます。
player.attack(monster)
モンスターの中でもゴーレムとかは、防御力が高そうです。 防御力の機能を実装したいとします。 このとき、上記の実装だと Player クラスは monster の属性 diffensive, life を知らないといけなくなります。
class Player:
def attack(self, monster):
monster.life -= monster.diffensive * self.offensive
# ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
# モンスターの中身を知らないといけない。
「何が問題なの?」って感じなのです。 Player クラスの中身を知らないといけないので、 Monster と Player クラスは、お互いに密結合になってしまいます。 密結合の何が問題かは、ここが神なので見てください。
これを無理やり「単一責任」の原則と絡めて、 副作用を受けるオブジェクトが責任を持っている、 責任を持っているオブジェクトがレシーバになるということにして以下のように書き換えて見ます。
monster.damaged(player.attack())
class Player:
def attack():
return self.offensive
class Monster:
def damaged(self, offensive):
self.life -= self.diffensive * offensive
「変更する理由が同じものは集める、変更する理由が違うものは分ける。」 良いデザインの基本原則を1つあげるとすればこれでしょう。
単一責任原則 - プログラマが知るべき97のこと (opens new window)
すると Player と Monster はお互いを知らずに済むようになりました。 本来の「単一責任」の意図とは違いますが、 副作用をベースにして、メソッドをどちらに寄せるかを考えると楽になるのかなと思います。 責任を持つ → 副作用を持つメソッドを持っている。 単純化しすぎると痛い目を見ると思うのですが、いまの自分の理解はこの程度です。
ここで、さらにプレイヤーとモンスターに属性 attribute があったとします。 火、水、木です。 水は火に強く、火は木に強く、木は水に強いとします。
すると一見して、今度こそモンスターには、プレイヤー player を引数として渡し、 そしてモンスターはプレイヤーを知らないといけないような気がします。
monster.damaged(player)
class Player:
def attack(self):
return self.offensive
class Monster:
def damaged(self, player):
# 相性の良し悪し
compability = dispatch(self.attribute, player.attribute)
# 純粋なダメージ
attack = self.diffensive * player.offensive
# 受けるダメージ = 相性の良し悪し X 純粋なダメージ
damage = compability * attack
#
self.life -= damage
これを無理やり依存性逆転の法則と絡めて、インターフェイス (攻撃力, 属性) に依存するようにしましょう。 インターフェイスとカッコつけて言いましたが、ようはタプルです。 これでまた Monster と Player はお互いを知らなくて済むようになりました。 代わりに attack (攻撃力, 属性) というインターフェイスを知らないといけないのですが。
monster.damaged(player.attack())
class Player:
def attack(self):
return self.offensive, self.attribute
class Monster:
def damaged(self, attack):
# 相性の良し悪し
compability = dispatch(self.attribute, attack.attribute)
# 純粋なダメージ
attack = self.diffensive * attack.offensive
# 受けるダメージ = 相性の良し悪し X 純粋なダメージ
damage = compability * attack
#
self.life -= damage
両方のレイヤーは上位レベルレイヤーが要求する振る舞いを表現した抽象に依存すべきである。
依存性逆転の原則 - Wikipedia (opens new window)
個人的には関係ないですが依存性逆転の原則と絡めて interface で規定してしまうのが、 いいのかなと思ったりします。 依存性逆転と聞くと難しそうですが、「全部渡すな必要なものだけ渡せ」っていう経験則かなと...
必要なものだけ渡すと疎結合にはなりますが、面倒です。 このあたりのさじ加減は、ここの判断というところなのでしょうか。
副作用をベースにしてなるべく疎結合にしたメソッドの作り方を見てきました。 以下の記事のシリーズは結構面白いです。
以下の記事では役割をベースにしてクラスを分割することを示してくれています。 とても勉強になります。オブジェクト指向は物じゃないって、 何を指しているのかが初めてわかりました。
全部イミュータブルということにします。そして、部分的に命名規則でミュータブルにする方法が考えられます。
オプショナルなイミュータブル(命名規則)
全て immutable として、
ただし、末尾にアンダーバーをつけたら val_ mutable のような形で、
命名規則で判別するくらいが Python らしくていいかなと感じます。
__init__ メソッドの中だけ代入を許す。
class User:
def __init__(self, name):
self.name = name # 名前は変えないので immutable
self.life_ = 100 # 体力は可変なので mutable
ただ、これはこれで PEP 8 の予約や組み込み型と被った時に使う命名規則と被ってしまうのですが...
アルファベットと _ なので、これ以外良いものが見当たらなかったからです。
変数の左右をアンダーバー _ で囲われると特殊属性と近いニュアンも出ますしね。
関数の引数名が予約語と衝突していた場合、アンダースコアを引数名の後ろに追加するのが一般的には望ましいです。 衝突した名前を変更しようとして、略語を使ったりスペルミスをするよりマシです。 よって、
class_はclssより好ましいです。 (多分、同義語を使って衝突を避けるのがよいのでしょうけど)
関数やメソッドに渡す引数 - PEP 8 (opens new window)
すこしずつ immutability を導入しようと思ったときに、 全てを immutable とするやり方がベストな気がします。 逆に immutable な場所を明示するやり方は、 結局面倒で使われなる恐れがあります。
Java ではフィールド、Python で言うところの属性です。 先頭に final をつけると変更できなくなるらしいです。 では Java のコードは final 祭りなのかなと言うと、どうもそう言う文化ではなさそうです。
だからと言っても、再代入を推奨するわけではありません。 finalなんて付けなくても、 どうせ再代入なんてしないのです。 あってもなくても一緒ならあるだけノイズです。 ... 中略 ... 最後になりますが、デフォルトで final がいいです。 わざわざ書きたくない。再代入可能の方にだけ宣言したい。と言う願望で締めとします。
finalを付けるのをやめてみた - 日々常々 (opens new window)
Javaのfinal,JSのconst,Scalaのval、 いずれも再代入を防ぐだけでオブジェクトは変更可能という 中途半端な機能で恩恵が少ないのでそう考えてしまうのも仕方ないですね。 この点においては、C++のconstやRustのデフォルトが正しい。
megumin1 氏のコメント 2019/09/28 08:51 (opens new window)
静的型付け言語である Java でさえ「immutable を明示するのは面倒だな...」みたいな文化です。 さらに動的型付けで緩い Python で immutable を明示するという命名規則を採用しても、 面倒になってやらなくなるのが目に見えています。
実は PEP 8 には、既に immutable を定めた規約があります。 immutable が大事だよって言われていますが、誰も属性レベルでは使っていません。 じゃあこれ使えばいいじゃんって話なのですが、大文字は読みにくいので... なまじ逆だったら良かったのですが。 変数は大文字で、定数は小文字にして欲しかったです。
定数 - PEP 8 (opens new window)
定数は通常モジュールレベルで定義します。 全ての定数は大文字で書き、単語をアンダースコアで区切ります。 例としてMAX_OVERFLOWやTOTALがあります。
例えば、属性をカプセル化するとき
Python は __attr ではなく _attr が主流になっています。
通常フェールセーフに倒すのが定石です。
しかし、既にこのような文化が定着してしまっています。 なぜ、このこの文化が定着してしまったのでしょうか。 背景は2つあるように感じます。
まず第一にPython が生まれた頃は、まだオブジェクト指向に未成熟でした。
また第二に、二重のアンダーバーが単純に __ が見づらいし、書きにくいからだと思います。
副作用に対応策を以下3点見てきました。
答え: しない方がいい気がします。
近年生まれた Rust は mutable を厳密に管理し、JavaScript は ES6 で const を導入しました。 Python も、このビックウェーブに乗るべきなのでしょうか?

現在でさえ Python のダブルアンダースコア __ あるいは定数の大文字 CONST は、
面倒でそこまで積極的に使われていません。
静的型付け言語である Java でさえ final をつければ immutable にできるけど、 でも面倒だと言う記事を見つけました。
もし仮に Python でもオプショナルで immutable にできる機能ができても、 Java の final が面倒であるのと、 同じような空気感になって使わなくなる気がします。
後方互換性を切ってまでイミュータブル導入すると言う選択肢も考えられます。 しかし、個人的には、そういった選択は取られないんじゃないかなと思っています。
Python 2 から Python 3 へと移行する際も、量の寡多はわからないのですが、とても苦労しているのを見かけました。 もうすでに Java, Kotlin, TypeScript とある中で その苦労を負ってまで、後方互換性を切ってまで来てくれる人がいないと思うからです。
加えて、後方互換性を切る変更は2度としない、という共通認識にあるそうです。
Python 2 と Python 3 のような、Python コードに影響する大きな非互換変更は 2 度としないというのは開発者の共通認識になっています。 (もともと Python 3 自体が時期的に大きな変更をする最後のチャンスだと踏んでやりすぎたので)
Python 4とPython 3の一番大きな違いは何ですか? - Quora (opens new window)
ここまで以下のように見てきました。
副作用は可読性、実装面の両方において、とても重要です。 しかし残念なことに Python では immutable の恩恵に預かることができないので、 各個に工夫して mutable を管理して行く必要があります。
次は関数型プログラミング言語 Lisp から導入された map, filter, lambda 関数を見ていきます。